GPT - это General-Purpose Technology: ранний взгляд на потенциальное влияние больших языковых моделей на рынок труда
- 1 Введение
- 2 Обзор литературы
- 3 Методы и сбор данных
- 4 Результаты
- 5 Валидация измерений
- 6 Обсуждение
- 7 Заключение
- Приложение A. Рубрикация воздействия
- Приложение B. O*NET Определения базовых навыков
- Приложение C. Воздействие на промышленность и производительность
- Приложение D. Профессии без задач, подверженных воздействию
- Ссылки
Дата публикации: 22 августа 2023 г.
Авторы:
- Тина Элунду (OpenAI)
- Сэм Мэннинг (OpenAI, OpenResearch)
- Памела Мишкин (OpenAI)
- Дэниел Рок (Университет Пенсильвании)
Аннотация:
Мы исследуем потенциальные последствия больших языковых моделей (LLM), таких как генеративные предварительно обученные трансформеры (GPT), для рынка труда США, уделяя особое внимание расширению возможностей, возникающих в результате использования программного обеспечения на базе LLM по сравнению с самими LLM. Используя новую рубрику, мы оцениваем профессии на основе их соответствия возможностям LLM, интегрируя как человеческий опыт, так и классификации GPT-4. Наши результаты показывают, что около 80% рабочей силы США могут столкнуться с тем, что по крайней мере 10% их рабочих задач будут затронуты внедрением LLM, в то время как примерно 19% работников могут столкнуться с тем, что по крайней мере 50% их задач будут затронуты. Мы не делаем прогнозов относительно сроков разработки или внедрения таких LLM. Прогнозируемые последствия охватывают все уровни заработной платы, причем более высокооплачиваемые рабочие места потенциально подвержены большему воздействию возможностей LLM и программного обеспечения на базе LLM. Важно отметить, что эти последствия не ограничиваются отраслями с более высоким недавним ростом производительности. Наш анализ показывает, что при наличии доступа к LLM около 15% всех рабочих задач в США могут быть выполнены значительно быстрее при том же уровне качества. При включении программного обеспечения и инструментов, созданных на основе LLM, эта доля увеличивается до 47-56% всех задач. Этот вывод подразумевает, что программное обеспечение на базе LLM окажет существенное влияние на масштабирование экономических последствий базовых моделей. Мы приходим к выводу, что LLM, такие как GPT, обладают чертами General Purpose Technology, что указывает на то, что они могут иметь значительные экономические, социальные и политические последствия.
1 Введение
Как показано на Рисунке 1, последние годы, месяцы и недели ознаменовались значительным прогрессом в области генеративного ИИ и больших языковых моделей (LLM). Хотя общественность часто ассоциирует LLM с различными итерациями генеративного предварительно обученного трансформера (GPT), LLM могут быть обучены с использованием ряда архитектур и не ограничиваются моделями на основе трансформеров (Devlin et al., 2019). LLM могут обрабатывать и производить различные формы последовательных данных, включая язык ассемблера, последовательности белков и шахматные партии, выходя за рамки одних лишь приложений на естественном языке. В этой статье мы используем LLM и GPT в некоторой степени взаимозаменяемо и указываем в нашей рубрике, что их следует считать похожими на семейство моделей GPT, доступных через ChatGPT или OpenAI Playground (которые на момент маркировки включали модели семейства GPT-3.5, но не семейства GPT-4). Мы изучаем LLM с возможностями генерации текста и кода, используем термин «генеративный ИИ» для дополнительного включения модальностей, таких как изображения или аудио, и используем «программное обеспечение на базе LLM» для обозначения инструментов, созданных на основе LLM или объединяющих LLM с другими моделями генеративного ИИ.
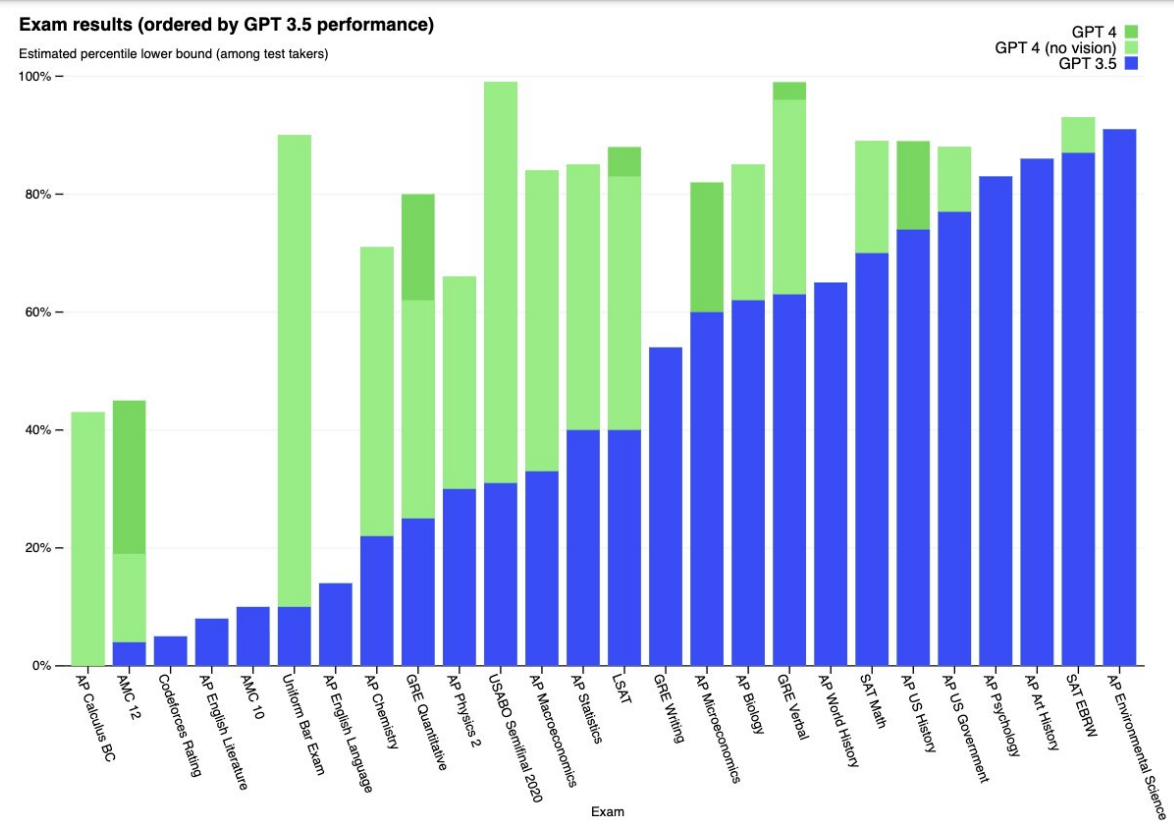 Рисунок 1: Взято непосредственно из технического отчета GPT-4 (OpenAI, 2023b). Чтобы получить представление о том, насколько быстро прогрессируют возможности модели, обратите внимание на скачок в результатах экзаменов между GPT-3.5 и GPT-4 (OpenAI, 2023b).
Рисунок 1: Взято непосредственно из технического отчета GPT-4 (OpenAI, 2023b). Чтобы получить представление о том, насколько быстро прогрессируют возможности модели, обратите внимание на скачок в результатах экзаменов между GPT-3.5 и GPT-4 (OpenAI, 2023b).
Однако наше исследование мотивировано не столько прогрессом самих этих моделей, сколько широтой, масштабом и возможностями, которые мы наблюдаем в дополнительных технологиях, разработанных на их основе. Роль дополнительных технологий еще предстоит определить, но максимизация влияния LLM, по-видимому, зависит от их интеграции с более крупными системами (Bresnahan, 2019; Agrawal et al., 2021). Хотя основное внимание в нашем обсуждении уделяется в первую очередь генеративным возможностям LLM, важно отметить, что эти модели также могут использоваться для решения различных задач, выходящих за рамки генерации текста. Например, вложения из LLM можно использовать для пользовательских поисковых приложений, а LLM могут выполнять такие задачи, как обобщение и классификация, где контекст может в значительной степени содержаться в промпте.
Чтобы дополнить прогнозы воздействия технологий на работу и создать основу для понимания развивающегося ландшафта языковых моделей и связанных с ними технологий, мы предлагаем новую рубрику для оценки возможностей LLM и их потенциального воздействия на рабочие места. Эта рубрика (A.1) измеряет общее воздействие задач на LLM, следуя духу предыдущих работ по количественной оценке воздействия машинного обучения (Brynjolfsson et al., 2018; Felten et al., 2018; Webb, 2020). Мы определяем воздействие как показатель потенциального экономического эффекта, не делая различий между эффектами увеличения или вытеснения труда. Мы используем аннотаторов-людей и сам GPT-4 в качестве классификатора, чтобы применить эту рубрику к данным о профессиях в экономике США, в основном полученным из базы данных O*NET.1 2
1 Это отличается от недавних исследований в области социальных наук, в которых LLM используются для моделирования поведения человека (Horton, 2023; Sorensen et al., 2022).
2 Хотя наша рубрика воздействия не обязательно увязывает концепцию языковых моделей с какой-либо конкретной моделью, мы были сильно мотивированы наблюдаемыми нами возможностями GPT-4 и набором возможностей, которые мы видели в разработке с партнерами по запуску OpenAI (OpenAI, 2023b).
Чтобы создать наш основной набор данных о воздействии, мы собрали как аннотации людей, так и классификации GPT-4, используя промпт, настроенный на согласованность с выборкой меток от авторов. Мы наблюдаем аналогичную согласованность уровней в ответах GPT-4 и между оценками человека и машины при агрегировании до уровня задачи. Эта мера воздействия отражает оценку технической возможности сделать человеческий труд более эффективным; однако социальные, экономические, нормативные и другие детерминанты подразумевают, что техническая осуществимость не гарантирует производительности труда или результатов автоматизации. Наш анализ показывает, что примерно 19% рабочих мест имеют по крайней мере 50% задач, подверженных воздействию, если рассматривать как текущие возможности модели, так и ожидаемые инструменты, созданные на ее основе. Оценки людей показывают, что только у 3% работников в США более половины задач подвержены воздействию LLM, если рассматривать существующие возможности языка и кода без дополнительного программного обеспечения или модальностей. С учетом других генеративных моделей и дополнительных технологий, по нашим оценкам, до 49% работников могут иметь половину или более своих задач, подверженных воздействию LLM.
Наши результаты последовательно показывают как в аннотациях людей, так и в аннотациях GPT-4, что большинство профессий демонстрируют некоторую степень воздействия LLM, причем уровни воздействия различаются в зависимости от типа работы. Профессии с более высокой заработной платой, как правило, демонстрируют более высокий уровень воздействия, что противоречит аналогичным оценкам общего воздействия машинного обучения (Brynjolfsson et al., 2023). Когда мы регрессируем показатели воздействия на наборы навыков, используя рубрику навыков O*NET, мы обнаруживаем, что роли, сильно зависящие от науки и навыков критического мышления, демонстрируют отрицательную корреляцию с воздействием, в то время как навыки программирования и письма положительно связаны с воздействием LLM. Следуя Autor et al. (2022a), мы изучаем барьеры для входа по «рабочим зонам» и обнаруживаем, что профессиональное воздействие LLM слабо возрастает с увеличением сложности подготовки к работе. Другими словами, работники, сталкивающиеся с более высокими (более низкими) барьерами для входа на свои рабочие места, как правило, испытывают большее (меньшее) воздействие LLM.
Далее мы сравниваем наши измерения с предыдущими работами, документирующими распределение воздействия автоматизации в экономике, и получаем в целом сопоставимые результаты. Большинство других показателей воздействия технологий, которые мы изучаем, статистически значимо коррелируют с нашим предпочтительным показателем воздействия, в то время как показатели рутинности ручного труда и воздействия робототехники демонстрируют отрицательные корреляции. Дисперсия, объясняемая этими более ранними работами (Acemoglu and Autor, 2011a; Frey and Osborne, 2017; Brynjolfsson et al., 2018; Felten et al., 2018; Webb, 2020; Brynjolfsson et al., 2023), наряду с контролем заработной платы, колеблется от 60 до 72%, что указывает на то, что от 28 до 40% вариации в нашем показателе воздействия ИИ остаются необъясненными предыдущими измерениями воздействия технологий.
Мы анализируем воздействие по отраслям и обнаруживаем, что отрасли, связанные с обработкой информации (4-значный NAICS), демонстрируют высокий уровень воздействия, в то время как обрабатывающая промышленность, сельское хозяйство и горнодобывающая промышленность демонстрируют более низкий уровень воздействия. Связь между ростом производительности за последнее десятилетие и общим воздействием LLM представляется слабой, что предполагает потенциально оптимистичный случай, когда будущий рост производительности от LLM может не усугубить возможные последствия «болезни издержек» (Baumol, 2012; Aghion et al., 2018).3
3 «Болезнь издержек» Баумоля — это теория, объясняющая, почему стоимость трудоемких услуг, таких как здравоохранение и образование, со временем увеличивается. Это происходит потому, что заработная плата квалифицированных работников в других отраслях растет, но в этих отраслях услуг не происходит соответствующего повышения производительности или эффективности. Следовательно, стоимость рабочей силы в этих отраслях становится относительно более дорогой по сравнению с другими товарами и услугами в экономике.
Наш анализ показывает, что воздействие LLM, таких как GPT-4, вероятно, будет повсеместным. Хотя возможности LLM со временем неуклонно улучшались, ожидается, что их растущее экономическое влияние сохранится и усилится, даже если мы остановим разработку новых возможностей сегодня. Мы также обнаруживаем, что потенциальное влияние LLM значительно расширяется, если принять во внимание разработку дополнительных технологий. В совокупности эти характеристики подразумевают, что генеративные предварительно обученные трансформеры (GPT) являются General Purpose Technology (GPT).4 (Bresnahan and Trajtenberg, 1995; Lipsey et al., 2005).
4 В оставшейся части статьи мы прописываем термин «технологии общего назначения», когда он используется вне утверждения «GPT — это GPT».
(Goldfarb et al., 2023) утверждают, что машинное обучение как широкая категория, вероятно, является технологией общего назначения. Наши данные свидетельствуют о более широком влиянии, поскольку даже подмножества программного обеспечения для машинного обучения независимо соответствуют критериям статуса технологии общего назначения. Основной вклад этой статьи заключается в предоставлении набора измерений потенциала воздействия LLM и демонстрации примера применения LLM для эффективной и масштабной разработки таких измерений. Кроме того, мы демонстрируем потенциал LLM как технологии общего назначения. Если «GPT — это GPT», то возможная траектория развития и применения LLM может быть сложной для регулирования политиками. Как и в случае с другими технологиями общего назначения, большая часть потенциала этих алгоритмов будет проявляться в широком спектре экономически ценных вариантов использования, включая создание новых видов работ (Acemoglu and Restrepo, 2018; Autor et al., 2022a). Наше исследование служит для измерения того, что технически осуществимо сейчас, но обязательно упустит развивающийся потенциал воздействия LLM с течением времени. Статья построена следующим образом: в разделе 2 рассматриваются соответствующие предыдущие работы, в разделе 3 обсуждаются методы и сбор данных, в разделе 4 представлены сводные статистические данные и результаты, в разделе 5 наши измерения соотносятся с предыдущими работами, в разделе 6 обсуждаются результаты, а в разделе 7 даются заключительные замечания.
2 Обзор литературы
2.1 Развитие больших языковых моделей
В последние годы модели генеративного ИИ привлекли значительное внимание как со стороны сообщества исследователей искусственного интеллекта (ИИ), так и со стороны широкой общественности благодаря своей способности решать широкий спектр сложных задач, основанных на языке. Прогресс в способностях этих моделей был обусловлен множеством факторов, включая увеличение количества параметров модели, больший объем обучающих данных и улучшенные конфигурации обучения (Brown et al., 2020; Radford et al., 2019; Hernandez et al., 2021; Kaplan et al., 2020). Широкие, передовые LLM, такие как LaMDA (Thoppilan et al., 2022) и GPT-4 (OpenAI, 2023b), преуспевают в различных приложениях, таких как перевод, классификация, творческое письмо и генерация кода — возможности, которые ранее требовали специализированных, ориентированных на конкретные задачи моделей, разработанных опытными инженерами с использованием данных, специфичных для предметной области.
Одновременно исследователи улучшили управляемость, надежность и полезность этих моделей, используя такие методы, как тонкая настройка и обучение с подкреплением на основе обратной связи от человека (Ouyang et al., 2022; Bai et al., 2022). Эти усовершенствования повышают способность моделей распознавать намерения пользователя, делая их более удобными и практичными. Более того, недавние исследования показывают, что LLM могут программировать и управлять другими цифровыми инструментами, такими как API, поисковые системы и даже другие системы генеративного ИИ (Schick et al., 2023; Mialon et al., 2023; Chase, 2022). Это обеспечивает бесшовную интеграцию отдельных компонентов для повышения полезности, производительности и обобщения. В пределе эти тенденции предполагают мир, в котором LLM могут быть способны выполнять любую задачу, обычно выполняемую на компьютере.
Модели генеративного ИИ в основном использовались в качестве модульных специалистов, выполняющих определенные задачи, такие как создание изображений на основе подписей или транскрибирование текста из речи. Однако мы утверждаем, что важно рассматривать LLM как универсальные строительные блоки для создания дополнительных инструментов. Разработка этих инструментов и их интеграция в системы потребует времени и, возможно, значительной реконфигурации существующих процессов в различных отраслях. Тем не менее, мы уже наблюдаем зарождающиеся тенденции внедрения. Несмотря на свои ограничения, LLM все чаще интегрируются в специализированные приложения в таких областях, как помощь в написании текстов, программировании и юридических исследованиях. Эти специализированные приложения затем позволяют предприятиям и частным лицам внедрять LLM в свои рабочие процессы.
Мы подчеркиваем важность этих дополнительных технологий, отчасти потому, что готовые LLM общего назначения могут оставаться ненадежными для различных задач из-за таких проблем, как фактические неточности, присущие предвзятости, проблемы конфиденциальности и риски дезинформации (Abid et al., 2021; Schramowski et al., 2022; Goldstein et al., 2023; OpenAI, 2023a). Однако специализированные рабочие процессы, включая инструменты, программное обеспечение или системы с участием человека, могут помочь устранить эти недостатки за счет включения опыта в конкретной предметной области. Например, Casetext предлагает инструменты юридического поиска на основе LLM, которые предоставляют юристам более быстрые и точные результаты юридического поиска, используя вложения и обобщение, чтобы противодействовать риску того, что GPT-4 может предоставить неточные сведения о юридическом деле или наборе документов. GitHub Copilot — это помощник по программированию, который использует LLM для генерации фрагментов кода и автозаполнения кода, которые пользователи затем могут принять или отклонить на основе своего опыта. Другими словами, хотя это правда, что сам по себе GPT-4 не «знает, который час», достаточно просто дать ему часы.
Кроме того, может возникнуть положительная обратная связь, когда LLM превзойдут определенный порог производительности, что позволит им помогать в создании инструментов, которые повышают их полезность и удобство использования в различных контекстах. Это может снизить стоимость и инженерный опыт, необходимые для создания таких инструментов, потенциально еще больше ускоряя внедрение и интеграцию LLM (Chen et al., 2021; Peng et al., 2023). LLM также могут стать ценными активами при разработке моделей машинного обучения, выступая в качестве помощников по программированию для исследователей, служб разметки данных или генераторов синтетических данных. Существует потенциал для того, чтобы такие модели вносили свой вклад в принятие экономических решений на уровне задач, например, путем уточнения методов распределения задач и подзадач между людьми и машинами (Singla et al., 2015; Shahaf and Horvitz, 2010). По мере того как LLM со временем совершенствуются и лучше соответствуют предпочтениям пользователей, мы можем ожидать постоянного улучшения производительности. Однако важно признать, что эти тенденции также несут в себе ряд серьезных рисков (Khlaaf et al., 2022; Weidinger et al., 2022; Solaiman et al., 2019).
2.2 Экономические последствия технологий автоматизации
Большое и растущее количество литературы посвящено влиянию технологий ИИ и автоматизации на рынок труда. Концепция технологических изменений, ориентированных на навыки, и модель задач автоматизации, часто рассматриваемая как стандартная основа для понимания влияния технологий на труд, возникла в результате исследований, демонстрирующих, что технический прогресс повышает спрос на квалифицированных работников по сравнению с неквалифицированными (Katz and Murphy, 1992). Многочисленные исследования основывались на этой концепции, изучая влияние технологических изменений и автоматизации на работников в рамках модели задач (Autor et al., 2003; Acemoglu and Autor, 2011b; Acemoglu and Restrepo, 2018). Это направление исследований показало, что работники, выполняющие рутинные и повторяющиеся задачи, подвергаются более высокому риску вытеснения, вызванного технологиями, — явление, известное как технологические изменения, ориентированные на рутину. Более поздние исследования выявили различия между эффектами вытеснения задач технологиями и эффектами восстановления задач (когда новые технологии увеличивают потребность в более широком спектре трудоемких задач) (Acemoglu and Restrepo, 2018, 2019). Несколько исследований показали, что технологии автоматизации привели к неравенству в оплате труда в США, вызванному относительным снижением заработной платы работников, специализирующихся на рутинных задачах (Autor et al., 2006; Van Reenen, 2011; Acemoglu and Restrepo, 2022b).
В предыдущих исследованиях использовались различные подходы для оценки пересечения между возможностями ИИ и задачами и действиями, выполняемыми работниками в различных профессиях. Эти методы включают сопоставление описаний патентов с описаниями задач работников (Webb, 2020; Meindl et al., 2021), увязку возможностей ИИ с профессиональными способностями, задокументированными в базе данных O*NET (Felten et al., 2018, 2023), сопоставление оценок эталонных задач ИИ с задачами работников через когнитивные способности (Tolan et al., 2021), маркировку потенциала автоматизации для подмножества профессий США и использование классификаторов машинного обучения для оценки этого потенциала для всех остальных профессий США (Frey and Osborne, 2017), моделирование автоматизации на уровне задач и агрегирование результатов до уровня профессии (Arntz et al., 2017), сбор экспертных прогнозов (Grace et al., 2018) и, что наиболее актуально для этой статьи, разработку новой рубрики для оценки деятельности работников на предмет их пригодности для машинного обучения (Brynjolfsson et al., 2018, 2023). Некоторые из этих подходов показали, что воздействие технологий ИИ на уровне задач, как правило, диверсифицировано в рамках профессии. Рассматривая каждую работу как набор задач, редко можно найти профессию, в которой инструменты ИИ могли бы выполнять почти всю работу. (Autor et al., 2022a) также обнаружили, что воздействие автоматизации и аугментации, как правило, положительно коррелирует. Также растет число исследований, изучающих конкретные экономические последствия и возможности LLM (Bommasani et al., 2021; Felten et al., 2023; Korinek, 2023; Mollick and Mollick, 2022; Noy and Zhang, 2023; Peng et al., 2023). Наряду с этими работами наши измерения помогают охарактеризовать более широкий потенциал актуальности языковых моделей для рынка труда. Технологии общего назначения (например, печать, паровой двигатель) характеризуются повсеместным распространением, постоянным совершенствованием и генерацией дополнительных инноваций (Bresnahan and Trajtenberg, 1995; Lipsey et al., 2005). Их далеко идущие последствия, которые разворачиваются на протяжении десятилетий, трудно предвидеть, особенно в отношении спроса на рабочую силу (Bessen, 2018; Korinek and Stiglitz, 2018; Acemoglu et al., 2020; Benzell et al., 2021). Для реализации полного потенциала технологий общего назначения требуется обширное совместное изобретение (Bresnahan and Trajtenberg, 1995; Bresnahan et al., 1996, 2002; Lipsey et al., 2005; Dixon et al., 2021) — дорогостоящий и трудоемкий процесс, включающий открытие новых бизнес-процедур (David, 1990; Bresnahan, 1999; Frey, 2019; Brynjolfsson et al., 2021; Feigenbaum and Gross, 2021). Следовательно, многие исследования технологий машинного обучения сосредоточены на внедрении на системном уровне, утверждая, что организационные системы могут потребовать редизайна, чтобы эффективно использовать новые достижения в области машинного обучения (Bresnahan, 2019; Agrawal et al., 2021; Goldfarb et al., 2023). Надлежащим образом спроектированные системы могут принести значительную коммерческую ценность и повысить эффективность работы компании (Rock, 2019; Babina et al., 2021; Zolas et al., 2021), а инструменты ИИ облегчают процесс открытия (Cockburn et al., 2018; Cheng et al., 2022). Используя информацию на уровне задач для оценки того, удовлетворяют ли LLM критериям технологии общего назначения, мы стремимся объединить эти две точки зрения для понимания взаимосвязи между технологиями и трудом.
Мы пытаемся развить эти разнообразные направления литературы несколькими способами. Вслед за (Felten et al., 2023) мы фокусируем наш анализ на влиянии LLM, а не на рассмотрении технологий машинного обучения или автоматизации в более широком смысле. Кроме того, мы предлагаем новый метод, который использует LLM, в частности GPT-4, для оценки задач на предмет воздействия и потенциала автоматизации, тем самым усиливая усилия людей по оценке. Впоследствии мы агрегируем наши результаты по профессиям и отраслям, фиксируя общее потенциальное воздействие на современный рынок труда США.
3 Методы и сбор данных
3.1 Данные о видах деятельности и задачах, выполняемых в рамках профессии в США
Мы используем базу данных O*NET 27.2 (O*NET, 2023), которая содержит информацию о 1016 профессиях, включая их соответствующие детализированные рабочие операции (DWA) и задачи. DWA — это комплексное действие, являющееся частью выполнения задачи, например «Изучение сценариев для определения требований проекта». Задача, с другой стороны, представляет собой специфическую для профессии единицу работы, которая может быть связана с нулевым, одним или несколькими DWA. Мы предлагаем выборку задач и DWA в Таблице 1. Два набора данных, которые мы используем, состоят из:
- 19 265 задач, состоящих из «описания задачи» и соответствующей профессии, и
- 2087 DWA, где большинство DWA связаны с одной или несколькими задачами, а задачи могут быть связаны с одним или несколькими DWA, хотя некоторые задачи не имеют связанных DWA.
3.2 Данные о заработной плате, занятости и демографии
Мы получаем данные о занятости и заработной плате из серии данных о профессиональной занятости за 2020 и 2021 годы, предоставленной Бюро статистики труда. Этот набор данных охватывает профессиональные звания, количество работников в каждой профессии, а также прогнозы занятости на уровне профессий на 2031 год, типичное образование, необходимое для начала работы по профессии, и обучение на рабочем месте, необходимое для достижения компетентности в профессии (BLS, 2022). Мы используем рекомендованный BLS кросс-индекс к O*NET (BLS, 2023b), чтобы связать набор данных задач и DWA O*NET и демографические данные рабочей силы BLS (BLS, 2023a), которые получены из Обследования текущего населения (CPS). Оба этих источника данных собираются правительством США и в основном охватывают работников, которые не являются самозанятыми, зарегистрированы и работают в так называемой формальной экономике.
3.3 Воздействие
Мы представляем наши результаты на основе рубрики воздействия, в которой мы определяем воздействие как меру того, сократит ли доступ к LLM или системе на базе LLM время, необходимое человеку для выполнения определенной DWA или выполнения задачи как минимум на 50 процентов. Хотя GPT-4 обладает способностью распознавания изображений (OpenAI, 2023b), а «LLM» часто используется для обозначения гораздо более широкого спектра модальностей, возможности распознавания изображений были включены только в наше определение программного обеспечения на базе LLM. Ниже приведено краткое описание нашей рубрики, а полная рубрика находится в разделе A.1. Если у нас есть метки для DWA, мы сначала агрегируем их до уровня задачи, а затем до уровня профессии.
Краткое описание воздействия
Отсутствие воздействия (E0), если:
- использование описанной LLM не приводит к сокращению или приводит к минимальному сокращению времени, необходимого для выполнения действия или задачи при сохранении эквивалентного качестваa, или
- использование описанной LLM приводит к снижению качества выполнения действия/задачи.
Прямое воздействие (E1), если:
- использование описанной LLM через ChatGPT или площадку OpenAI может сократить время, необходимое для выполнения DWA или задачи, как минимум наполовину (50%).
Воздействие LLM+ (E2), если:
- доступ к описанной LLM сам по себе не сократит время, необходимое для выполнения действия/задачи, как минимум наполовину, но
- можно разработать дополнительное программное обеспечение на базе LLM, которое могло бы сократить время, необходимое для выполнения конкретного действия/задачи с сохранением качества, как минимум наполовину. К таким системам мы относим доступ к системам генерации изображений.b
a Эквивалентное качество означает, что третья сторона, обычно получатель результата, не заметит помощь LLM или не будет возражать против нее.
bНа практике, как видно из полной рубрики в Приложении A.1, мы отдельно классифицируем доступ к возможностям распознавания изображений (E3) для облегчения аннотирования, хотя мы объединяем E2 и E3 для всех анализов.
Таблица 1
Пример профессий, задач и детализированных рабочих операций из базы данных O*NET.
| ID задачи | Название профессии | DWA | Описание задачи |
|---|---|---|---|
| 14675 | Инженеры/архитекторы компьютерных систем | Мониторинг производительности компьютерной системы для обеспечения надлежащей работы. | Мониторинг работы системы для выявления потенциальных проблем. |
| 18310 | Медсестры интенсивной терапии | Эксплуатация диагностических или терапевтических медицинских инструментов или оборудования. | Настройка, эксплуатация или мониторинг инвазивного оборудования и устройств, таких как оборудование для колостомии или трахеотомии, аппараты искусственной вентиляции легких, катетеры, желудочно-кишечные зонды и центральные линии. |
| Подготовка медицинских принадлежностей или оборудования к использованию. | |||
| 4668.0 | Кассиры игорных заведений | Осуществление продаж или других финансовых операций. | Обналичивание чеков и обработка авансов по кредитным картам для посетителей. |
| 15709 | Онлайн-продавцы | Осуществление продаж или других финансовых операций. | Отправка по электронной почте подтверждения завершенных транзакций и отгрузки. |
| 6529 | Воспитатели детских садов, кроме специального образования | Привлечение родителей-волонтеров и старших учеников к занятиям с детьми для облегчения участия в целенаправленной, комплексной игре. | |
| 6568 | Учителя начальных классов, кроме специального образования | Привлечение родителей-волонтеров и старших учеников к занятиям с детьми для облегчения участия в целенаправленной, комплексной игре. |
Мы видим, что агрегирование только по видам деятельности является неточным, о чем свидетельствует тот факт, что мы ожидаем, что кассиры игорных заведений будут выполнять данное DWA лично, используя некоторую физическую силу, в то время как мы ожидаем, что онлайн-продавцы будут выполнять ту же деятельность исключительно с помощью компьютера.
Мы установили порог воздействия на уровне потенциального 50%-ного сокращения времени, необходимого для выполнения конкретного DWA или задачи при сохранении постоянного качества. Мы ожидаем, что внедрение будет наиболее высоким и наиболее непосредственным для приложений, которые обеспечивают значительное повышение производительности. Хотя этот порог является несколько произвольным, он был выбран для облегчения интерпретации аннотаторами. Более того, независимо от выбранного порога, мы предположили, что реальное сокращение времени выполнения задачи, вероятно, будет немного или значительно ниже наших оценок, что побудило нас выбрать относительно высокий порог. В нашей собственной проверочной маркировке мы обнаружили, что это тесно связано с тем, может ли LLM или программное обеспечение на базе LLM выполнять основную часть задачи или почти всю задачу.
Сравнение
| Сравнение | y | Вес | Согласие | Пирсона |
|---|---|---|---|---|
| GPT-4, Рубрика 1; Человек | α | E1 | 80,8% | 0,223 |
| β | E1+.5*E2 | 65,6% | 0,591 | |
| ζ | E1+E2 | 82,1% | 0,654 | |
| GPT-4, Рубрика 2; Человек | α | E1 | 81,8% | 0,221 |
| β | E1+.5*E2 | 65,6% | 0,538 | |
| ζ | E1+E2 | 79,5% | 0,589 | |
| GPT-4, Рубрика 1; GPT-4, Рубрика 2 | α | E1 | 91,1% | 0,611 |
| β | E1+.5*E2 | 76,0% | 0,705 | |
| ζ | E1+E2 | 82,4% | 0,680 |
Таблица 2: Сравнение моделей и людей по согласию и корреляции Пирсона. Оценка согласия определяется путем определения того, насколько часто две группы согласуются по аннотации (например, E0, E1 или E2). В статье мы используем GPT-4, Рубрика 1. Основным задачам присваивается двойной вес на уровне профессии по сравнению с дополнительными задачами. Все веса в сумме дают единицу.
Затем мы собрали аннотации, сгенерированные людьми и GPT-4, используя рубрику воздействия, которые лежат в основе большей части анализа в этой статье.
- Оценки людей: Мы получили аннотации людей, применив рубрику к каждой детализированной рабочей операции (DWA) O*NET и подмножеству всех задач O*NET, а затем агрегировали эти оценки DWA и задач до уровня задачи и профессии. Авторы лично разметили большую выборку задач и DWA и привлекли опытных аннотаторов-людей, которые просматривали выходные данные GPT-3, GPT-3.5 и GPT-4 в рамках работы OpenAI по выравниванию (Ouyang et al., 2022).
- Оценки GPT-4: Мы применили аналогичную рубрику к ранней версии GPT-4 (OpenAI, 2023b), но для всех пар задача/профессия, а не для DWA. Мы внесли незначительные изменения в рубрику (которая в данном случае использовалась в качестве «подсказки» для модели), чтобы улучшить согласованность с набором человеческих меток. Полные показатели согласованности приведены в Таблице 2.
Мы строим три основных показателя для нашей зависимой переменной, представляющей интерес: (i) α, соответствующий El в рубрике воздействия выше, который, как ожидается, будет представлять нижнюю границу доли подверженных воздействию задач в рамках профессии, (ii) β, который представляет собой сумму El и 0,5*E2, где вес 0,5 для E2 предназначен для учета воздействия, когда развертывание технологии с помощью дополнительных инструментов и приложений требует дополнительных инвестиций, и (iii) ζ, сумма El и E2, верхняя граница воздействия, которая дает оценку максимального воздействия LLM и программного обеспечения на базе LLM. Мы обобщаем согласованность между группами аннотаций и показателями в Таблице 2. Для оставшейся части анализа, если не указано иное, читатель может предположить, что мы имеем в виду воздействие β — то есть все задачи, непосредственно подверженные воздействию через такие инструменты, как ChatGPT или площадка OpenAI, считаются подверженными воздействию в два раза сильнее, чем задачи, требующие некоторой дополнительной инновации.
5Авторы аннотировали DWA, которые явно требовали высокой степени физической активности или ловкости рук, а привлеченные аннотаторы разметили оставшиеся виды деятельности, а также подмножество задач, включая задачи без связанных DWA и задачи, для которых не было четкой аннотации на уровне задачи после агрегирования аннотаций DWA.
3.4 Ограничения нашей методологии
3.4.1 Субъективные суждения людей
Фундаментальное ограничение нашего подхода заключается в субъективности маркировки. В нашем исследовании мы используем аннотаторов, знакомых с возможностями LLM. Однако эта группа не является разнообразной в профессиональном плане, что потенциально может привести к предвзятым суждениям относительно надежности и эффективности LLM при выполнении задач в рамках незнакомых профессий. Мы признаем, что получение высококачественных меток для каждой задачи в профессии требует привлечения работников, занятых в этих профессиях, или, как минимум, обладающих глубокими знаниями о различных задачах в рамках этих профессий. Это представляет собой важную область для будущей работы по проверке этих результатов.
3.4.2 Измерение LLM с помощью GPT-4
Недавние исследования показывают, что GPT-4 служит эффективным дискриминатором, способным применять сложные таксономии и реагировать на изменения в формулировках и акцентах (OpenAI, 2023b). Результаты классификации задач GPT-4 чувствительны к изменениям в формулировках рубрики, порядку и составу подсказки, наличию или отсутствию конкретных примеров в рубрике, уровню детализации и определениям, данным для ключевых терминов. Итерация подсказки на основе наблюдаемых результатов в небольшом проверочном наборе может повысить согласованность между выходными данными модели и замыслом рубрики. Следовательно, существуют небольшие различия между рубрикой, представленной людям, и рубрикой, используемой для GPT-4. Это решение было принято сознательно, чтобы направить модель к разумным меткам, не оказывая чрезмерного влияния на аннотаторов-людей. В результате мы используем несколько источников аннотаций, но ни один из них не следует считать окончательной истиной по отношению к другим. В этом анализе мы представляем результаты аннотаторов-людей в качестве наших основных результатов. Дальнейшее улучшение и инновации в разработке эффективных рубрик для классификации LLM остаются возможными. Тем не менее, мы наблюдаем высокую степень согласованности между оценками людей и оценками GPT-4 на уровне профессии в отношении общего воздействия систем LLM (см. Таблицу 2, Рисунок 2).
3.4.3 Дополнительные недостатки
- Достоверность модели задач. Неясно, в какой степени профессии можно полностью разбить на задачи, и систематически ли этот подход опускает определенные категории навыков или задач, которые неявно требуются для компетентного выполнения работы. Кроме того, задачи могут состоять из подзадач, некоторые из которых более автоматизируемы, чем другие. Некоторые задачи могут функционировать как предшественники других задач, так что выполнение последующих задач зависит от задач-предшественников. Если действительно разбиение на задачи не является достоверным представлением того, как выполняется большая часть работы в профессии, наш анализ воздействия будет в значительной степени недействительным.
- Отсутствие экспертизы и интерпретация задач. Аннотаторы-люди в основном не знали о конкретных профессиях, сопоставленных с каждым DWA, в процессе маркировки. Это привело к неясной логике агрегирования задач и профессий, а также к некоторым очевидным расхождениям в метках, продемонстрированным в Таблице 1. Мы экспериментировали с различными методами агрегирования и обнаружили, что даже при подходе максимального сопоставления (при котором берется совпадающая метка человек<>модель, если таковая существует) согласованность оставалась относительно постоянной. В конечном итоге мы собрали дополнительные метки для пар задача/профессия, по которым были значительные разногласия.
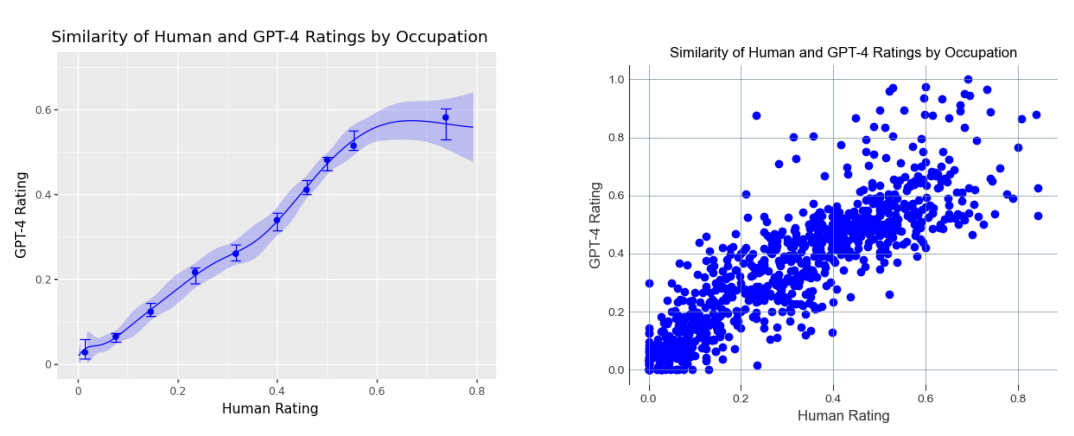
Рисунок 2: Оценки людей (ось x) и оценки GPT-4 (ось y) показывают высокую степень согласованности в отношении воздействия LLM по профессиям. Мы вычисляем воздействие на уровне профессии на этих рисунках путем усреднения воздействия на уровне задач в соответствии с методом β. O*NET обозначает некоторые задачи как «основные», а другие как «дополнительные». Основным задачам присваивается двойной вес по сравнению с дополнительными задачами, и все веса в сумме дают единицу. Вблизи самых высоких уровней воздействия в соответствии с методом β агрегирования оценок воздействия по профессиям оценки GPT-4, как правило, ниже, чем оценки людей. Мы представляем необработанный точечный график и бинскаттер. Вблизи верхнего предела оценок воздействия люди в среднем чаще оценивают профессию как подверженную воздействию.
- Перспективный и подверженный изменениям, с некоторыми ранними данными. Точное прогнозирование будущих приложений LLM остается серьезной проблемой даже для экспертов (OpenAI, 2023b). Открытие новых эмерджентных возможностей, изменения в предвзятости восприятия людей и сдвиги в технологическом развитии — все это может повлиять на точность и надежность прогнозов относительно потенциального воздействия LLM на задачи работников и разработку программного обеспечения на базе LLM. Наши прогнозы по своей сути являются перспективными и основаны на текущих тенденциях, данных и представлениях о технологических возможностях. В результате они могут измениться по мере появления новых достижений в этой области. Например, некоторые задачи, которые сегодня кажутся маловероятными для воздействия LLM или программного обеспечения на базе LLM, могут измениться с появлением новых возможностей модели. И наоборот, задачи, которые кажутся подверженными воздействию, могут столкнуться с непредвиденными проблемами, ограничивающими применение языковых моделей.
-
Источники разногласий. Хотя мы не проводили строгого изучения источников разногласий, мы обнаружили несколько мест, где люди и модель, как правило, «застревали» в своих оценках:
- Задачи или действия, в которых, хотя LLM теоретически могла бы помочь или выполнить задачу, ее внедрение для этого потребовало бы от нескольких человек изменить свои привычки или ожидания (например, встречи, переговоры),
- Задачи или действия, в которых в настоящее время существует некоторое регулирование или норма, которая требует или предполагает человеческий надзор, суждение или эмпатию (например, принятие решений, консультирование), и
- Задачи или действия, для которых уже существует технология, которая может разумно автоматизировать задачу (например, бронирование).
4 Результаты
Технологии общего назначения встречаются относительно редко и характеризуются повсеместным распространением, совершенствованием с течением времени и разработкой значительных сопутствующих изобретений и побочных эффектов (Lipsey et al., 2005). Наша оценка потенциального влияния LLM на рынок труда ограничено, поскольку она не учитывает совокупную производительность факторов производства или потенциал капиталовложений. Помимо влияния на рабочую силу, LLM могут также влиять на эти аспекты. На данном этапе одни критерии технологий общего назначения оценить легче, чем другие. Наша основная задача на данном раннем этапе — проверить гипотезу о том, что LLM оказывают повсеместное влияние на экономику, аналогично подходу, использованному (Goldfarb et al., 2023), которые проанализировали распространение машинного обучения через объявления о вакансиях, чтобы оценить его статус как технологии общего назначения. Вместо использования объявлений о вакансиях или изучения машинного обучения в целом, мы применяем подход оценки задач с использованием аннотаций как людей, так и GPT-4. Этот анализ может показать, ограничено ли воздействие определенным набором схожих задач или профессий, или же оно будет более широким.
Наши результаты показывают, что, исходя из возможностей LLM на уровне задач, они могут существенно повлиять на широкий спектр профессий в экономике США, демонстрируя ключевой атрибут технологий общего назначения. В следующих разделах мы обсудим результаты по различным ролям и структурам заработной платы. Дополнительные результаты по относительному воздействию отраслей в экономике США можно найти в Приложении C.
4.1 Сводные статистические данные
Сводные статистические данные по этим показателям можно найти в Таблице 3. Как аннотации людей, так и аннотации GPT-4 показывают, что средние значения α на уровне профессии находятся в диапазоне от 0,14 до 0,15, что предполагает, что в среднем примерно 15% задач в рамках профессии непосредственно подвержены воздействию LLM.6 Этот показатель увеличивается до более чем 30% для β и превышает 50% для ζ. По совпадению, аннотации людей и GPT-4 также отмечают от 15% до 14% всех задач в наборе данных как подверженные воздействию LLM. Исходя из значений β, мы оцениваем, что 80% работников относятся к профессиям, в которых по крайней мере 10% задач подвержены воздействию LLM, в то время как 19% работников относятся к профессиям, в которых более половины задач помечены как подверженные воздействию.
Мы провели один набор анализов с использованием оценок «важности» O*NET, но не обнаружили существенных изменений в наших результатах. Хотя мы признаем, что отсутствие взвешивания относительной важности задачи для данной профессии дает некоторые любопытные результаты (например, рейтинг парикмахеров как имеющих достаточно высокое воздействие).
Хотя потенциал воздействия на задачи огромен, LLM и программное обеспечение на базе LLM должны быть интегрированы в более широкие системы, чтобы полностью реализовать этот потенциал. Как это часто бывает с технологиями общего назначения, барьеры для совместного изобретения могут первоначально препятствовать быстрому распространению GPT в экономических приложениях. Кроме того, прогнозирование необходимости человеческого надзора является сложной задачей, особенно для задач, где возможности модели равны или превосходят человеческий уровень. Хотя требование человеческого надзора может первоначально замедлить скорость распространения этих систем в экономике, пользователи LLM и систем на базе LLM, вероятно, со временем будут все больше знакомиться с этой технологией, особенно в плане понимания того, когда и как доверять ее результатам.
4.2 Заработная плата и занятость
На Рисунке 3 мы представляем интенсивность воздействия по всей экономике. Каждая точка на графике отображает воздействие профессии, где значение по оси x представляет долю задач профессии, которые подвержены воздействию (на каждом уровне α, β и ζ), а значение по оси y представляет долю всех профессий США с такой долей подверженных воздействию задач. Например, аннотаторы-люди определили, что 2,3% профессий подвержены воздействию α50, 21,6% подвержены воздействию β50 и 47,3% подвержены воздействию ζ50, где порог 50% берется из оси x, а процент профессий берется из оси y. В любой заданной точке на оси x вертикальное расстояние между α и ζ представляет собой потенциал воздействия, обусловленный инструментами и приложениями, помимо прямого воздействия LLM. Все задачи в рамках профессии на этом рисунке имеют равный вес.
6Мы вычисляем оценки на уровне профессии для Таблицы 3, присваивая двойной вес задачам, обозначенным как «основные» O*NET, по сравнению с задачами, обозначенными как «дополнительные». Все веса задач в сумме дают единицу в рамках профессии.
Таблица 3
Сводные статистические данные по данным о воздействии людей и моделей.
| Показатель | Люди | GPT-4 | ||
|---|---|---|---|---|
| Среднее | Стд. | Среднее | Стд. | |
| Воздействие на уровне профессии | ||||
| α | 0,14 | 0,14 | 0,14 | 0,16 |
| β | 0,30 | 0,21 | 0,34 | 0,22 |
| ζ | 0,46 | 0,30 | 0,55 | 0,34 |
| Воздействие на уровне задачи | ||||
| α | 0,15 | 0,36 | 0,14 | 0,35 |
| β | 0,31 | 0,37 | 0,35 | 0,35 |
| ζ | 0,47 | 0,50 | 0,56 | 0,50 |
Задачам, обозначенным как основные задачи для профессии, присваивается двойной вес по сравнению с теми, которые указаны как дополнительные в файле задач O*NET.
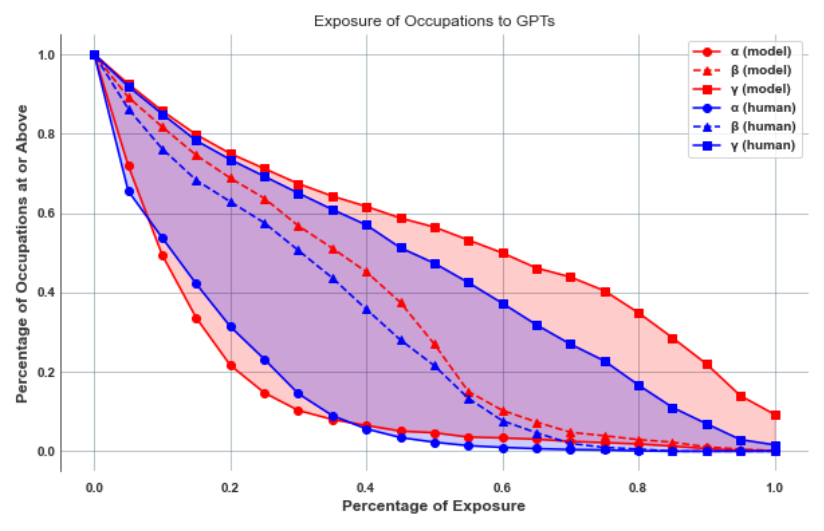
Рисунок 3: Интенсивность воздействия в экономике, выраженная в процентах от затронутых профессий. Данная точка данных показывает процент профессий с воздействием ниже заданного порога. В предыдущей версии этой статьи две метки на графике были перепутаны, что привело к перестановке ответов людей и моделей. На этом рисунке всем задачам в рамках профессии присваивается равный вес.
При агрегировании на уровне профессии аннотации людей и GPT-4 демонстрируют качественное сходство и имеют тенденцию к корреляции, как показано на Рисунке 4. Аннотации людей оценивают незначительно более низкое воздействие для высокооплачиваемых профессий по сравнению с аннотациями GPT-4. Хотя существует множество низкооплачиваемых профессий с высоким уровнем воздействия и высокооплачиваемых профессий с низким уровнем воздействия, общая тенденция на бинскаттерном графике показывает, что более высокая заработная плата связана с повышенным воздействием LLM.7
Потенциальное воздействие LLM, по-видимому, мало коррелирует с текущим уровнем занятости. На Рисунке 4 как оценки людей, так и оценки GPT-4 общего воздействия агрегированы до уровня профессии (ось y) и сопоставлены с логарифмом общей занятости (ось x). Ни один из графиков не выявляет существенных различий в воздействии LLM при разном уровне занятости.
7При агрегировании задач до уровня профессии мы присваиваем половину веса дополнительным задачам O*NET по сравнению с основными задачами.
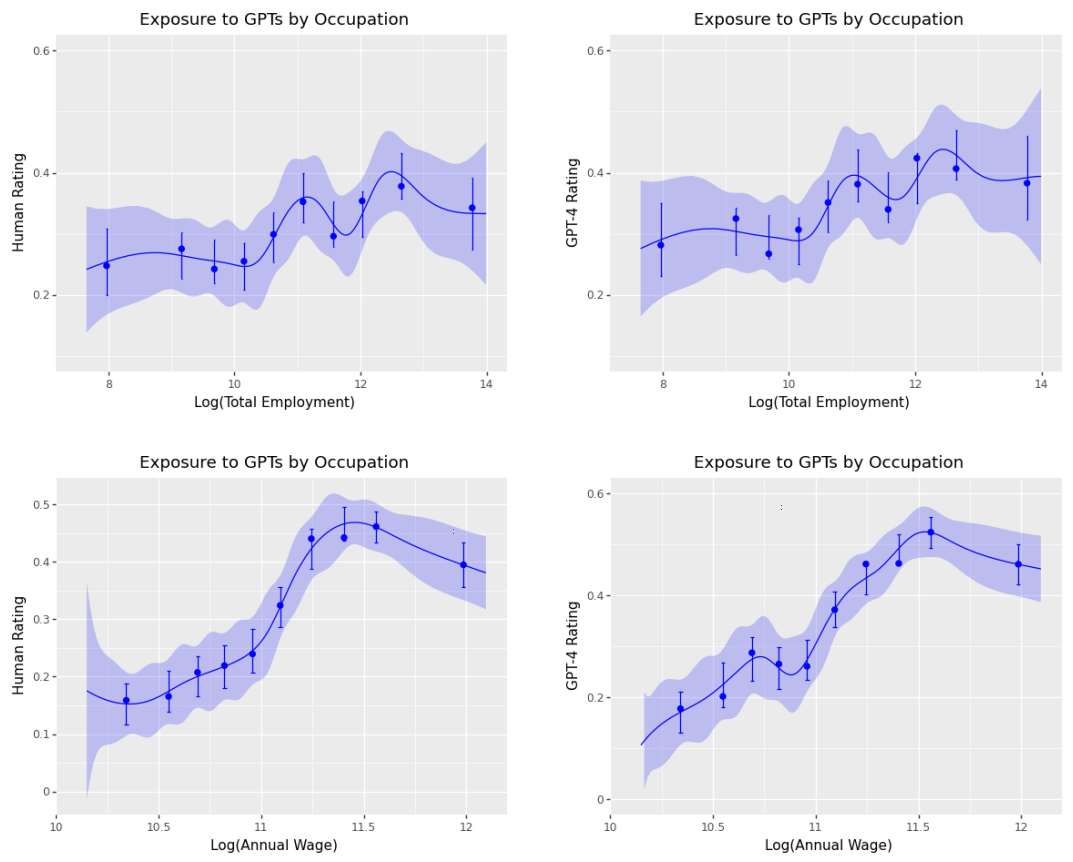
Рисунок 4: Бинскаттерные графики отображают воздействие языковых моделей (LLM) на различные профессии, оцененное как людьми, так и GPT-4. Эти графики сравнивают воздействие LLM и частичного программного обеспечения на базе LLM (β) на уровне профессии с логарифмом общей занятости в рамках профессии и логарифмом средней годовой заработной платы для профессий. Хотя существуют некоторые расхождения, как оценки людей, так и оценки GPT-4 показывают, что профессии с более высокой заработной платой, как правило, более подвержены воздействию LLM. Кроме того, многочисленные профессии с более низкой заработной платой демонстрируют высокое воздействие на основе нашей рубрики. Основным задачам присваивается двойной вес по сравнению с дополнительными задачами в рамках профессий при расчете средних оценок воздействия. Данные о занятости и заработной плате взяты из опроса BLS-OES, проведенного в мае 2021 года. При агрегировании задач до уровня профессии мы присваиваем половину веса дополнительным задачам O*NET по сравнению с основными задачами. Все веса в рамках профессии в сумме дают единицу.
4.3 Важность навыков
В этом разделе мы исследуем взаимосвязь между важностью навыка для профессии (в соответствии с аннотациями в наборе данных O*NET) и нашими показателями воздействия. Во-первых, мы используем базовые навыки, предоставляемые O*NET (определения навыков можно найти в Приложении B), и нормализуем показатель важности навыков для каждой профессии, чтобы повысить понятность результатов. Далее мы проводим регрессионный анализ наших показателей воздействия (α, β, ζ), чтобы изучить силу связи между важностью навыков и воздействием.
Наши результаты показывают, что важность научных навыков и навыков критического мышления сильно отрицательно связана с воздействием, что позволяет предположить, что профессии, требующие этих навыков, с меньшей вероятностью будут затронуты современными LLM. И наоборот, навыки программирования и письма демонстрируют сильную положительную связь с воздействием, подразумевая, что профессии, связанные с этими навыками, более подвержены влиянию LLM (подробные результаты см. в Таблице 5).
4.4 Барьеры для входа
Далее мы изучаем барьеры для входа, чтобы лучше понять, существует ли дифференциация воздействия в зависимости от типа работы. Одним из таких показателей является дескриптор уровня профессии O*NET, называемый «Рабочая зона». Рабочая зона объединяет профессии, схожие по (а) уровню образования, необходимому для получения работы по этой профессии, (b) объему соответствующего опыта, необходимого для выполнения работы, и (c) степени обучения на рабочем месте, необходимого для выполнения работы. В базе данных O*NET существует 5 рабочих зон, причем Рабочая зона 1 требует наименьшего объема подготовки (3 месяца), а Рабочая зона 5 — наиболее обширной подготовки, 4 года и более. Мы наблюдаем, что средний доход монотонно увеличивается по рабочим зонам по мере увеличения необходимого уровня подготовки: средний работник в Рабочей зоне 1 зарабатывает 30 230 долларов США, а средний работник в Рабочей зоне 5 — 80 980 долларов США.
Все наши показатели (α, β и ζ) демонстрируют идентичную картину, то есть воздействие увеличивается от Рабочей зоны 1 к Рабочей зоне 4 и либо остается неизменным, либо снижается в Рабочей зоне 5. Подобно Рисунку 3, на Рисунке 5 мы отображаем процент работников на каждом пороге воздействия. Мы обнаруживаем, что в среднем процент работников в профессиях с воздействием β более 50% в Рабочих зонах с 1 по 5 составляет 0,00% (Рабочая зона 1), 6,11% (Рабочая зона 2), 10,57% (Рабочая зона 3), 34,5% (Рабочая зона 4) и 26,45% (Рабочая зона 5) соответственно.8
8Для этого набора результатов всем задачам в рамках профессии присваивается равный вес. Результаты существенно не меняются при использовании схемы взвешивания «основные/дополнительные».
4.4.1 Типичное образование, необходимое для начала работы
Поскольку включение в Рабочую зону учитывает как требуемое образование — которое само по себе является показателем приобретения навыков, — так и требуемую подготовку, мы ищем данные, чтобы разделить эти переменные. Мы используем две переменные из данных Бюро статистики труда о профессиях: «Типичное образование, необходимое для начала работы» и «Обучение на рабочем месте, необходимое для достижения компетентности» по профессии. Изучая эти факторы, мы стремимся выявить тенденции с потенциальными последствиями для рабочей силы. У нас нет данных об образовании и требованиях к обучению на рабочем месте для 3 504 000 работников, поэтому они исключены из сводных таблиц.
Наш анализ показывает, что люди, имеющие степень бакалавра, магистра и ученую степень, больше подвержены воздействию LLM и программного обеспечения на базе LLM, чем те, кто не имеет формального образования (см. Таблицу 7). Интересно, что мы также обнаруживаем, что люди, имеющие некоторое высшее образование, но не имеющие степени, демонстрируют высокий уровень воздействия LLM и программного обеспечения на базе LLM. Изучив таблицу, отображающую барьеры для входа, мы видим, что работа с наименьшим воздействием требует наибольшего обучения, потенциально предлагая более низкую отдачу (с точки зрения среднего дохода) после достижения компетентности. И наоборот, работа, не требующая обучения на рабочем месте или требующая только стажировки/ординатуры, по-видимому, приносит более высокий доход, но более подвержена воздействию LLM.
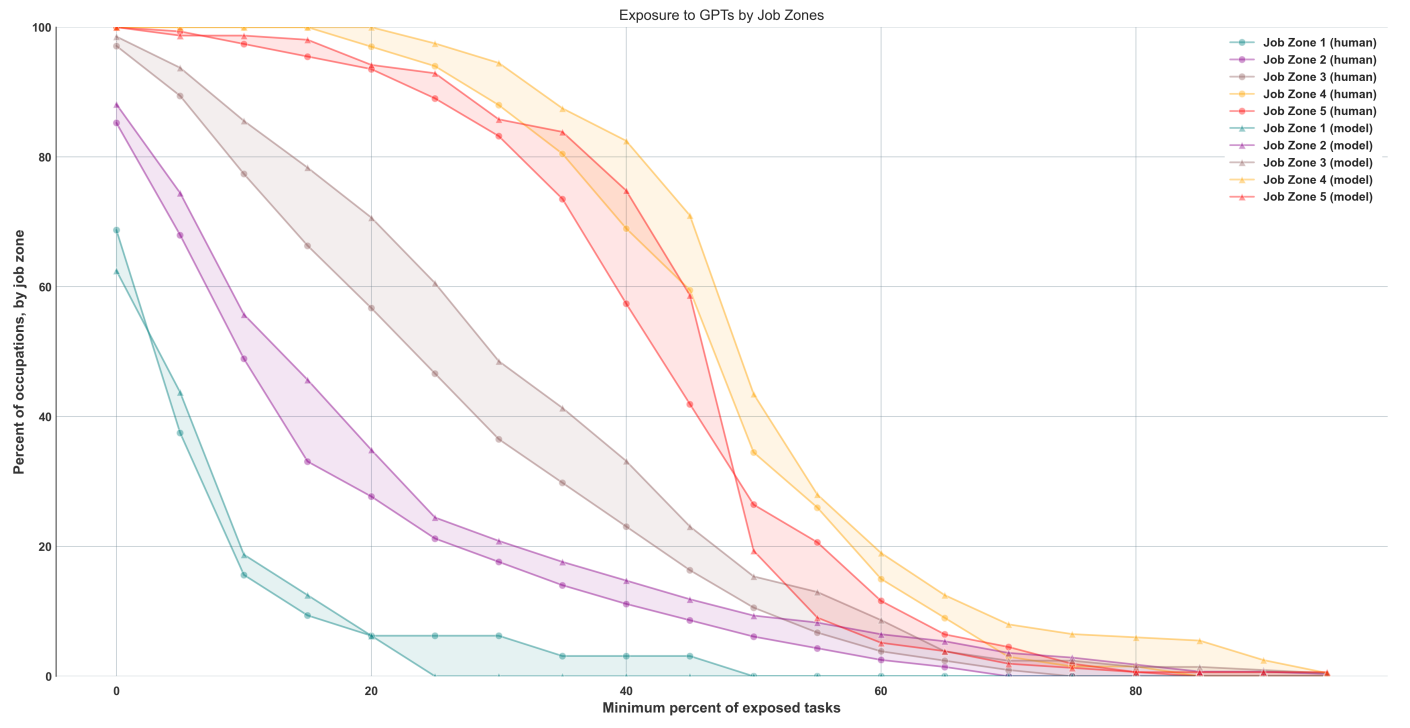
Рисунок 5: Оценки воздействия β по профессиям в пяти рабочих зонах, которые представляют собой группы схожих профессий, классифицированные в соответствии с уровнем образования, опыта и обучения на рабочем месте, необходимого для их выполнения. Всем задачам присваивается равный вес.
| Группа | Профессии с наивысшим воздействием | % воздействия | |
|---|---|---|---|
| Человек α | Переводчики | 76,5 | |
| Социологические опросы | 75,0 | ||
| Поэты, авторы текстов и писатели-творцы | 68,8 | ||
| Ученые-зоологи | 66,7 | ||
| Специалисты по связям с общественностью | 66,7 | ||
| Человек β | Социологические опросы | 84,4 | |
| Писатели и авторы | 82,5 | ||
| Переводчики | 82,4 | ||
| Специалисты по связям с общественностью | 80,6 | ||
| Ученые-зоологи | 77,8 | ||
| Человек ζ | Математики | 100,0 | |
| Специалисты по подготовке налоговых деклараций | 100,0 | ||
| Финансовые аналитики-кванты | 100,0 | ||
| Писатели и авторы | 100,0 | ||
| Дизайнеры веб-интерфейсов и цифровых интерфейсов | 100,0 | ||
| Люди отметили 15 профессий как «полностью подверженные воздействию». | |||
| Модель α | Математики | 100,0 | |
| Клерки по корреспонденции | 95,2 | ||
| Блокчейн-инженеры | 94,1 | ||
| Судебные репортеры и синхронные титровальщики | 92,9 | ||
| Корректоры и копирайтеры | 90,9 | ||
| Модель β | Математики | 100,0 | |
| Блокчейн-инженеры | 97,1 | ||
| Судебные репортеры и синхронные титровальщики | 96,4 | ||
| Корректоры и копирайтеры | 95,5 | ||
| Клерки по корреспонденции | 95,2 | ||
| Модель ζ | Бухгалтеры и аудиторы | 100,0 | |
| Аналитики новостей, репортеры и журналисты | 100,0 | ||
| Секретари по юридическим вопросам и административные помощники | 100,0 | ||
| Менеджеры клинических данных | 100,0 | ||
| Аналитики по вопросам политики в области изменения климата | 100,0 | ||
| Модель отметила 86 профессий как «полностью подверженные воздействию». | |||
| Наивысшая дисперсия | Специалисты по поисковому маркетингу | 14,5 | |
| Графические дизайнеры | 13,4 | ||
| Управляющие инвестиционными фондами | 13,0 | ||
| Финансовые менеджеры | 13,0 | ||
| Страховые оценщики, авто | 12,6 |
Таблица 4: Профессии с наивысшим воздействием по каждому показателю. В последней строке перечислены профессии с наивысшим значением σ2, что указывает на наибольшую вариабельность оценок воздействия. Проценты воздействия показывают долю задач профессии, подверженных воздействию GPT (α) или программного обеспечения на базе GPT (β и ζ), где воздействие определяется как сокращение времени, необходимого для выполнения задачи, как минимум на 50% (см. рубрику воздействия A.1). Таким образом, профессии, перечисленные в этой таблице, — это те, где, по нашим оценкам, GPT и программное обеспечение на базе GPT могут сэкономить работникам значительное количество времени на выполнение значительной части своих задач, но это не обязательно означает, что их задачи могут быть полностью автоматизированы этими технологиями. Всем задачам присваивается равный вес в рамках профессии.
| Базовый навык | α (станд. ошибка) | β (станд. ошибка) | ζ (станд. ошибка) |
|---|---|---|---|
| Все показатели важности навыков нормализованы в диапазоне от 0 до 1. | |||
| Константа | 0,082*** | -0,112*** | 0,300*** |
| (0,011) | (0,011) | (0,057) | |
| Активное слушание | 0,128** | 0,214*** | 0,449*** |
| (0,043) | (0,047) | (0,027) | |
| Математика | -0,127*** | 0,161*** | 0,787*** |
| (0,026) | (0,021) | (0,049) | |
| Понимание прочитанного | 0,153*** | 0,470*** | -0,346*** |
| (0,041) | (0,037) | (0,017) | |
| Наука | -0,114*** | -0,230*** | -0,346*** |
| (0,014) | (0,012) | (0,017) | |
| Говорение | -0,028 | 0,133*** | 0,294*** |
| (0,039) | (0,033) | (0,042) | |
| Письмо | 0,368*** | 0,467*** | 0,566*** |
| (0,042) | (0,037) | (0,047) | |
| Активное обучение | -0,157*** | -0,065** | 0,028 |
| (0,027) | (0,024) | (0,032) | |
| Критическое мышление | -0,264*** | -0,196*** | -0,129** |
| (0,036) | (0,033) | (0,042) | |
| Стратегии обучения | -0,072* | -0,209*** | -0,346*** |
| (0,028) | (0,025) | (0,034) | |
| Мониторинг | -0,067** | -0,149*** | -0,232*** |
| (0,023) | 0,020) | (0,026) | |
| Программирование | 0,637*** | 0,623*** | 0,609*** |
| (0,030) | (0,022) | (0,024) |
Таблица 5: Регрессия оценок воздействия GPT на уровне профессии, аннотированных людьми, на важность навыков для каждого навыка в категории базовых навыков O*NET, плюс навык программирования. Описания навыков можно найти в Приложении B. Оценки задач в рамках каждой профессии для воздействия имеют равный вес.
| Рабочая зона | Требуемая подготовка | Требуемое образование | Примеры профессий | Средний доход | Общая занятость (тыс.) | H α | M α | H β | M β | H ζ | M ζ |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Отсутствует или незначительная (0-3 месяца) | Средняя школа или GED (необязательно) | Работники пищевой промышленности, посудомойщики, шлифовщики полов | 30 230 | 13 100 | 0,03 | 0,04 | 0,06 | 0,06 | 0,09 | 0,08 |
| 2 | Некоторая (3-12 месяцев) | Средняя школа | Санитары, представители клиентской службы, кассиры | 38 215 | 73 962 | 0,07 | 0,12 | 0,16 | 0,20 | 0,24 | 0,27 |
| 3 | Средняя (1-2 года) | Профессиональное училище, обучение на рабочем месте или степень младшего специалиста | Электрики, парикмахеры, фельдшеры | 54 815 | 37 881 | 0,11 | 0,14 | 0,26 | 0,32 | 0,41 | 0,51 |
| 4 | Значительная (2-4 года) | Степень бакалавра | Системные администраторы баз данных, графические дизайнеры, сметчики | 77 345 | 56 833 | 0,23 | 0,18 | 0,47 | 0,51 | 0,71 | 0,85 |
| 5 | Обширная (4+ лет) | Степень магистра и выше | Фармацевты, юристы, астрономы | 81 980 | 21 221 | 0,23 | 0,13 | 0,43 | 0,45 | 0,63 | 0,76 |
Таблица 6: Среднее воздействие GPT по рабочим зонам. Для каждой рабочей зоны мы также представляем медиану среднего годового дохода для каждой составляющей профессии в долларах США и общее количество работников во всех профессиях для этой рабочей зоны в тысячах. Веса задач равны для всех задач.
| Требуемое обучение на рабочем месте | Медианный доход | Общая занятость (в тысячах) | Η α | Μ α | Η β | Μ β | Η ζ | Μ ζ |
|---|---|---|---|---|---|---|---|---|
| Отсутствует | 77 440 | 90 776 | 0,20 | 0,16 | 0,42 | 0,46 | 0,63 | 0,76 |
| Стажировка | 55 995 | 3 066 | 0,01 | 0,02 | 0,04 | 0,06 | 0,07 | 0,10 |
| Ординатура | 77 110 | 3 063 | 0,16 | 0,06 | 0,36 | 0,38 | 0,55 | 0,71 |
| Краткосрочное обучение на рабочем месте | 33 370 | 66 234 | 0,11 | 0,15 | 0,21 | 0,25 | 0,32 | 0,34 |
| Среднесрочное обучение на рабочем месте | 46 880 | 31 285 | 0,09 | 0,12 | 0,21 | 0,25 | 0,32 | 0,38 |
| Долгосрочное обучение на рабочем месте | 48 925 | 5 070 | 0,08 | 0,10 | 0,18 | 0,22 | 0,28 | 0,33 |
Таблица 7: Средние оценки воздействия для профессий, сгруппированные по уровню обучения на рабочем месте, необходимого для достижения компетентности в данной профессии. Наряду с оценками воздействия мы отображаем медиану среднего годового дохода для каждой профессии, а также общее количество работников в каждой группе в тысячах. Веса задач равны в рамках профессии и в сумме дают единицу.
5 Валидация измерений
5.1 Сравнение с предыдущими работами
Эта статья призвана развить ряд предыдущих эмпирических исследований, изучающих воздействие достижений в области ИИ и/или автоматизации на профессии. В предыдущих исследованиях использовались различные методы, в том числе:
- Использование таксономий профессий, таких как O*NET, для определения того, какие профессии связаны с рутинными, а какие с нерутинными, а также с ручными, а какие с когнитивными задачами (Autor et al., 2003; Acemoglu and Autor, 2011a).
- Сопоставление текстовых описаний задач с описаниями технологических достижений в патентах (Kogan et al., 2021; Webb, 2020).
- Увязка возможностей систем ИИ с профессиональными способностями и агрегирование оценок воздействия по профессиям, в которых эти способности необходимы (Felten et al., 2018, 2023).
- Сопоставление результатов эталонных оценок задач ИИ (ImageNet, Robocup и т. д.) с 59 задачами работников с помощью набора из 14 когнитивных способностей, взятых из литературы по когнитивной науке (Tolan et al., 2021).
- Экспертная оценка потенциала автоматизации для набора профессий O*NET, в отношении которых у экспертов была высокая степень уверенности, в сочетании с вероятностным классификатором для оценки потенциала автоматизации для остальных профессий O*NET (Frey and Osborne, 2017).
- Разработка рубрики для оценки «пригодности для машинного обучения» (SML) видов деятельности, выполняемых работниками в экономике (Brynjolfsson and Mitchell, 2017; Brynjolfsson et al., 2018, 2023).
Мы предоставляем набор сводных статистических данных по многим из этих предыдущих работ в Таблице 8.
Методология этой статьи в первую очередь основывается на подходе SML путем разработки рубрики для оценки пересечения между возможностями LLM и задачами работников, указанными в базе данных O*NET. В Таблице 9 представлены результаты OLS-регрессий наших новых измерений воздействия LLM на показатели воздействия на уровне профессии из (Felten et al., 2018) («Оценка воздействия ИИ на профессию» в таблице), (Frey and Osborne, 2017) («Автоматизация» Фрея и Осборна), оценки по всем трем технологиям в (Webb, 2020), нормализованные оценки ручных и когнитивных задач из (Acemoglu and Autor, 2011a) и (Brynjolfsson et al., 2018, 2023) (SML). Мы также используем годовые оклады по профессиям из последнего Обзора занятости BLS в качестве контрольного показателя. Существует четыре отдельные выходные переменные, представляющие новые оценки в этой статье, которые прогнозируются на основе предыдущих работ.
Оценка воздействия GPT-4 1 соответствует нашей общей рубрике воздействия, оцененной GPT-4, где полный потенциал воздействия кодируется как 1, отсутствие потенциала воздействия кодируется как 0, а частичное воздействие (E2 в нашей схеме маркировки) кодируется как 0,5. Оценка воздействия GPT-4 2 оценивается аналогично для общего воздействия, но с несколько иной подсказкой. Результаты по двум подсказкам очень похожи. Оценка воздействия человека представляет собой ту же рубрику, что и в Оценке воздействия GPT-4 1, но оценивается людьми, как обсуждалось в предыдущем разделе статьи. Эти результаты соответствуют набору статистических данных β, представленному выше, при этом дополнительным задачам присваивается половина веса основных задач в рамках профессии. Эти веса в сумме дают единицу (различия между основными и дополнительными задачами определяются O*NET).
Результаты по каждому типу измерений согласуются. Мы обнаруживаем в целом положительные и статистически значимые корреляции между нашими показателями воздействия LLM и предыдущими измерениями, ориентированными на программное обеспечение и ИИ. Обнадеживает тот факт, что оценки воздействия SML по профессиям демонстрируют значительную и положительную связь с оценками воздействия, которые мы разработали в этой статье, демонстрируя определенный уровень согласованности между двумя исследованиями с аналогичными подходами. Показатели, основанные на патентах на программное обеспечение и ИИ Уэбба, SML и нормализованные (центрированные и деленные на стандартное отклонение) оценки рутинных когнитивных задач демонстрируют положительную связь с некоторыми из наших показателей.
| Показатель | Мин. | 25-й перцентиль | Медиана | 75-й перцентиль | Макс. | Среднее | Стд. откл. | Кол-во |
|---|---|---|---|---|---|---|---|---|
| Оценка воздействия GPT-4 1 | 0,00 | 0,13 | 0,34 | 0,50 | 1,00 | 0,33 | 0,22 | 750 |
| Оценка воздействия GPT-4 2 | 0,00 | 0,09 | 0,24 | 0,40 | 0,98 | 0,26 | 0,20 | 750 |
| Оценка воздействия человека | 0,00 | 0,09 | 0,29 | 0,47 | 0,84 | 0,29 | 0,21 | 750 |
| Программное обеспечение (Уэбб) | 1,00 | 25,00 | 50,00 | 75,00 | 100,00 | 50,69 | 30,05 | 750 |
| Роботы (Уэбб) | 1,00 | 22,00 | 52,00 | 69,00 | 100,00 | 48,61 | 28,61 | 750 |
| ИИ (Уэбб) | 1,00 | 28,00 | 55,00 | 82,00 | 100,00 | 54,53 | 29,65 | 750 |
| Пригодность для машинного обучения | 2,60 | 2,84 | 2,95 | 3,12 | 3,55 | 2,99 | 0,18 | 750 |
| Нормализованная рутинная когнитивная | -3,05 | -0,46 | 0,10 | 0,63 | 3,42 | 0,07 | 0,86 | 750 |
| Нормализованная рутинная ручная | -1,81 | -0,81 | -0,11 | 0,73 | 2,96 | 0,05 | 1,01 | 750 |
| Оценка воздействия ИИ на профессию | 1,42 | 3,09 | 3,56 | 4,04 | 6,54 | 3,56 | 0,70 | 750 |
| Автоматизация по Фрею и Осборну | 0,00 | 0,07 | 0,59 | 0,88 | 0,99 | 0,50 | 0,38 | 681 |
| Логарифм средней заработной платы | 10,13 | 10,67 | 11,00 | 11,34 | 12,65 | 11,02 | 0,45 | 749 |
Таблица 8: Сводные статистические данные по ряду предыдущих работ по измерению воздействия ИИ и автоматизации на профессии. Мы также включили сводные статистические данные по измерениям, недавно представленным в этой работе. Мы включаем все показатели из (Webb, 2020), нормализованные оценки рутинных когнитивных и ручных задач из (Acemoglu and Autor, 2011a) (средние значения могут незначительно отличаться от 0 из-за неидеального сопоставления групп профессий), пригодность для машинного обучения из (Brynjolfsson and Mitchell, 2017; Brynjolfsson et al., 2018, 2023), воздействие ИИ на профессию из (Felten et al., 2018) и воздействие автоматизации из (Frey and Osborne, 2017). Мы включаем столько профессий, сколько можем сопоставить, но поскольку таксономии O*NET менялись по мере разработки этих показателей, некоторые роли могут отсутствовать в последней версии 6-значных профессий O*NET.
Программное обеспечение, SML и оценки рутинных когнитивных задач демонстрируют положительную и статистически значимую связь с оценками воздействия LLM на уровне 1%. Коэффициенты для оценок ИИ из (Webb, 2020) также положительны и статистически значимы на уровне 5%, но наша вторичная подсказка по общему воздействию LLM в столбцах 3 и 4 не демонстрирует статистически значимой связи. По большей части, оценка воздействия ИИ на профессию не коррелирует с нашими показателями воздействия. Оценки воздействия роботов Уэбба, содержание рутинных ручных задач и общий показатель автоматизации из (Frey and Osborne, 2017) отрицательно коррелируют с нашими основными оценками общего воздействия GPT-4 и оценками людей, условно по другим измерениям. Эта отрицательная корреляция отражает ограниченное воздействие LLM на физические задачи. Ручной труд не подвержен воздействию LLM или даже LLM с дополнительной системной интеграцией на данный момент.
Низкие корреляции с (Felten et al., 2018) и (Frey and Osborne, 2017) потенциально можно объяснить различиями в подходах. Увязка возможностей ИИ со способностями работников или оценка воздействия непосредственно на основе характеристик профессии, а не агрегирование до уровня профессии из DWA или оценок на уровне задач (как в статье SML и нашей собственной), предлагают несколько иную точку зрения на содержание профессий.
Во всех регрессиях R2 колеблется от 60,7% (столбец 3) до 72,8% (столбец 5). Это говорит о том, что наш показатель, который явно фокусируется на возможностях LLM, имеет от 28 до 40% необъяснимой дисперсии по сравнению с другими измерениями. Особенно в случае оценок воздействия, связанных с ИИ, мы ожидаем, что сочетание других измерений будет иметь сильную корреляцию с нашими оценками. Однако более ранние работы имели ограниченную информацию о будущем прогрессе LLM или программного обеспечения на базе LLM. Мы ожидаем, что наше понимание будущих технологий машинного обучения аналогичным образом будет несовершенно отражено в нашей сегодняшней рубрике.
| Оценка воздействия GPT-4 1 | Оценка воздействия GPT-4 2 | Оценка воздействия человека | ||||
|---|---|---|---|---|---|---|
| (1) | (2) | (3) | (4) | (5) | (6) | |
| Программное обеспечение (Уэбб) | 0,00113*** | 0,00123*** | 0,00111*** | 0,00119*** | 0,00096*** | 0,00101*** |
| (0,00031) | (0,00031) | (0,00031) | (0,00031) | (0,00031) | (0,00031) | |
| Роботы (Уэбб) | -0,00378*** | -0,00405*** | -0,00377*** | -0,00399*** | -0,00371*** | -0,00383*** |
| (0,00032) | (0,00031) | (0,00034) | (0,00033) | (0,00029) | (0,00028) | |
| ИИ (Уэбб) | 0,00080*** | 0,00090*** | 0,00036 | 0,00045 | 0,00067** | 0,00071** |
| (0,00030) | (0,00029) | (0,00030) | (0,00030) | (0,00030) | (0,00030) | |
| Пригодность для машинного обучения | 0,29522*** | 0,26888*** | 0,28468*** | 0,26245*** | 0,19514*** | 0,18373*** |
| (0,04503) | (0,04418) | (0,04404) | (0,04342) | (0,03990) | (0,03886) | |
| Нормализованная рутинная когнитивная | 0,06601*** | 0,06868*** | 0,04743*** | 0,05015*** | 0,03568*** | 0,03659*** |
| (0,00886) | (0,00894) | (0,00872) | (0,00879) | (0,00671) | (0,00669) | |
| Нормализованная рутинная ручная | -0,11147*** | -0,11371*** | -0,09390*** | -0,09561*** | -0,11045*** | -0,11152*** |
| (0,00785) | (0,00789) | (0,00817) | (0,00818) | (0,00741) | (0,00744) | |
| Оценка воздействия ИИ на профессию | 0,00993 | 0,02465** | -0,01537 | -0,00265 | 0,00630 | 0,01252 |
| (0,01107) | (0,01059) | (0,01160) | (0,01114) | (0,00918) | (0,00845) | |
| Автоматизация по Фрею и Осборну | -0,03024* | -0,03950** | -0,00364 | -0,01217 | -0,03890** | -0,04253** |
| (0,01835) | (0,01841) | (0,02007) | (0,01972) | (0,01883) | (0,01858) | |
| Логарифм средней заработной платы | 0,05804*** | 0,04863*** | 0,02531 | |||
| (0,01870) | (0,01860) | (0,01727) | ||||
| Константа | -1,12937*** | -0,45743*** | -0,96117*** | -0,39935*** | -0,47078* | -0,17706 |
| (0,26859) | (0,15327) | (0,26365) | (0,15017) | (0,24684) | (0,13256) | |
| N | 680,00000 | 681,00000 | 680,00000 | 681,00000 | 680,00000 | 681,00000 |
| R2 | 0,68741 | 0,68212 | 0,60737 | 0,60198 | 0,71213 | 0,71126 |
Таблица 9: Регрессия оценок воздействия LLM на предыдущие показатели воздействия ИИ и автоматизации на профессии. Мы также включаем среднегодовую заработную плату из опроса BLS-OES в мае 2021 года. Каждый показатель сохраняется в своем первоначальном масштабе, за исключением рутинных когнитивных и рутинных ручных оценок из (Acemoglu and Autor, 2011a). Эти две оценки стандартизированы до нулевого среднего значения и единичной дисперсии. Как правило, мы обнаруживаем сильные положительные связи с предыдущими работами, хотя все еще остается большая остаточная дисперсия, которая может быть объяснена нашими новыми показателями. Столбцы 1 и 2 основаны на нашем основном показателе воздействия β по оценкам GPT-4. Столбцы 3 и 4 основаны на аналогичной, несколько иной рубрике воздействия, также оцененной GPT-4 для обеспечения надежности. Столбцы 5 и 6 отражают оценки людей по той же рубрике, что и столбцы 1 и 2. Оценки на уровне профессии строятся с использованием весов задач «основные/дополнительные», при этом дополнительным задачам присваивается половина веса основных задач.
6 Обсуждение
6.1 GPT как технология общего назначения
Ранее в этой статье мы обсуждали возможность того, что LLM можно классифицировать как технологию общего назначения. Эта классификация требует, чтобы LLM соответствовали трем основным критериям: улучшение с течением времени, повсеместное распространение в экономике и способность порождать дополнительные инновации (Lipsey et al., 2005). Данные из литературы по ИИ и машинному обучению убедительно демонстрируют, что LLM соответствуют первому критерию — они улучшаются в своих возможностях с течением времени, обладая способностью выполнять или помогать в выполнении все более сложного набора задач и вариантов использования (см. 2.1). В этой статье представлены доказательства в поддержку двух последних критериев: LLM сами по себе могут оказывать повсеместное воздействие на экономику, а дополнительные инновации, основанные на LLM, — в частности, с помощью программного обеспечения и цифровых инструментов — могут иметь широкое применение в экономической деятельности.
Рисунок 3 дает одну иллюстрацию потенциального экономического воздействия дополнительного программного обеспечения, созданного на основе LLM. Разница по оси y (доля всех профессий) между α и ζ в заданной точке по оси x (доля задач в рамках профессии, которые подвержены воздействию) дает совокупный потенциал воздействия в рамках профессии, обусловленный инструментами и программным обеспечением, помимо прямого воздействия самих LLM. Разница в средних значениях по всем задачам между α и ζ, составляющая 0,42 при использовании аннотаций GPT-4 и 0,32 при использовании аннотаций людей (см. Рисунок 3), предполагает, что среднее воздействие программного обеспечения на базе LLM на уровень воздействия задач может быть более чем в два раза больше, чем среднее воздействие самих LLM (среднее значение α составляет 0,14 как на основе аннотаций людей, так и аннотаций GPT-4). Хотя наши результаты показывают, что эти модели «из коробки» актуальны для значительной доли работников и задач, они также показывают, что программные инновации, которые они порождают, могут оказать гораздо более широкое воздействие.
Одним из компонентов повсеместности технологии является уровень ее внедрения предприятиями и пользователями. В этой статье не проводится систематический анализ внедрения этих моделей, однако есть ранние качественные данные, свидетельствующие о том, что внедрение и использование LLM становится все более широким. Мощь относительно простых улучшений пользовательского интерфейса на основе LLM была очевидна при развертывании ChatGPT — в то время как версии базовой языковой модели ранее были доступны через API, использование резко возросло после выпуска интерфейса ChatGPT (Chow, 2023; OpenAI, 2022). После этого выпуска ряд коммерческих опросов показывает, что внедрение LLM компаниями и работниками за последние несколько месяцев увеличилось (Constantz, 2023; ResumeBuilder.com, 2023).
Широкое внедрение этих моделей требует устранения существующих узких мест. Ключевым фактором, определяющим их полезность, является уровень доверия, которое люди им оказывают, и то, как люди адаптируют свои привычки. Например, в юридической профессии полезность моделей зависит от того, смогут ли юристы доверять результатам модели без проверки оригиналов документов или проведения независимых исследований. Стоимость и гибкость технологии, предпочтения работников и фирм, а также стимулы также существенно влияют на внедрение инструментов, созданных на основе LLM. Таким образом, на внедрение может повлиять прогресс в решении некоторых этических проблем и проблем безопасности, связанных с LLM: предвзятость, фабрикация фактов и несогласованность, и это лишь некоторые из них (OpenAI, 2023a). Более того, внедрение LLM будет различаться в разных секторах экономики из-за таких факторов, как доступность данных, нормативно-правовая среда и распределение власти и интересов. Следовательно, всестороннее понимание внедрения и использования LLM работниками и фирмами требует более глубокого изучения этих тонкостей.
Одна из возможностей заключается в том, что экономия времени и бесшовное применение будут иметь большее значение, чем повышение качества, для большинства задач. Другая возможность заключается в том, что первоначальное внимание будет уделяться аугментации, а затем автоматизации (Huang and Rust, 2018). Одним из вариантов развития событий может стать этап аугментации, когда рабочие места сначала становятся более нестабильными (например, писатели становятся фрилансерами), а затем переходят к полной автоматизации.
6.2 Последствия для государственной политики США
Внедрение технологий автоматизации, включая LLM, ранее связывалось с усилением экономического неравенства и сбоями на рынке труда, которые могут привести к неблагоприятным последствиям (Acemoglu and Restrepo, 2022a; Acemoglu, 2002; Moll et al., 2021; Klinova and Korinek, 2021; Weidinger et al., 2021, 2022). Наши результаты изучения воздействия на работников в Соединенных Штатах подчеркивают необходимость общественной и политической готовности к потенциальному экономическому сбою, вызванному LLM и порождаемыми ими дополнительными технологиями. Хотя в задачи данной статьи не входит рекомендация конкретных политических мер для сглаживания перехода к экономике со все более широким распространением LLM, в предыдущих работах, таких как (Autor et al., 2022b), сформулирован ряд важных направлений политики США, связанных с образованием, обучением работников, реформами программ социальной защиты и многим другим.
6.3 Ограничения и будущая работа
Помимо упомянутых выше, мы особо выделяем некоторые ограничения данной работы, которые требуют дальнейшего изучения. Прежде всего, наш акцент на Соединенных Штатах ограничивает обобщаемость наших выводов на другие страны, где внедрение и влияние генеративных моделей могут отличаться из-за таких факторов, как промышленная организация, технологическая инфраструктура, нормативно-правовая база, языковое разнообразие и культурные особенности. Мы надеемся устранить это ограничение, расширив охват исследования и поделившись своими методами, чтобы другие исследователи могли на них опираться.
Последующие исследовательские работы должны рассмотреть два дополнительных исследования: одно посвящено изучению моделей внедрения LLM в различных секторах и профессиях, а другое — изучению реальных возможностей и ограничений самых современных моделей в отношении деятельности работников, выходящей за рамки наших оценок воздействия. Например, несмотря на недавние успехи в области мультимодальных возможностей GPT-4, мы не учитывали возможности распознавания изображений в оценках α прямого воздействия LLM (OpenAI, 2023b). В будущих работах следует учитывать влияние таких возможностей по мере их развития. Кроме того, мы признаем, что могут быть расхождения между теоретической и практической производительностью, особенно в сложных, открытых и специфичных для предметной области задачах.
7 Заключение
В заключение, это исследование предлагает изучение потенциального влияния LLM на различные профессии и отрасли в экономике США. Применив новую рубрику для понимания возможностей LLM и их потенциального воздействия на рабочие места, мы обнаружили, что большинство профессий демонстрируют некоторую степень воздействия LLM, причем профессии с более высокой заработной платой, как правило, имеют больше задач с высоким уровнем воздействия. Наш анализ показывает, что примерно 19% рабочих мест имеют по крайней мере 50% задач, подверженных воздействию LLM, если рассматривать как текущие возможности модели, так и ожидаемое программное обеспечение на базе LLM.
Наше исследование призвано подчеркнуть потенциал LLM как технологии общего назначения и их возможные последствия для работников США. Предыдущая литература демонстрирует впечатляющие улучшения LLM на сегодняшний день (см. 2.1). Наши результаты подтверждают гипотезу о том, что эти технологии могут оказывать повсеместное воздействие на широкий спектр профессий в США, а дополнительные достижения, поддерживаемые LLM, в основном за счет программного обеспечения и цифровых инструментов, могут оказывать существенное влияние на ряд видов экономической деятельности. Однако, хотя техническая способность LLM повышать эффективность человеческого труда представляется очевидной, важно признать, что социальные, экономические, нормативные и другие факторы будут влиять на фактические результаты производительности труда. По мере развития возможностей влияние LLM на экономику, вероятно, сохранится и усилится, создавая проблемы для политиков в прогнозировании и регулировании их траектории.
Необходимы дальнейшие исследования для изучения более широких последствий достижений LLM, включая их потенциал по увеличению или вытеснению человеческого труда, их влияние на качество рабочих мест, влияние на неравенство, развитие навыков и многие другие результаты. Стремясь понять возможности и потенциальные последствия LLM на рабочую силу, политики и заинтересованные стороны могут принимать более обоснованные решения для навигации в сложном ландшафте ИИ и его роли в формировании будущего труда.
7.1 Заключение LLM (версия GPT-4)
Генеративные предварительно обученные трансформеры (GPT) производят глубокие преобразования, обеспечивая потенциальный технологический рост, проникая в задачи и оказывая значительное влияние на профессии. Это исследование изучает потенциальные траектории GPT, представляя новаторскую рубрику для оценки воздействия GPT на задачи, особенно на рынке труда США.
7.2 Заключение LLM (дополненная автором версия)
Генеративные предварительно обученные трансформеры (GPT) производят глубокие преобразования, обеспечивая потенциальный технологический рост, проникая в задачи и уничтожая профессиональный менеджмент. Как оценить возможные траектории? Создавайте новаторские таксономии, собирайте политиков вместе, обобщайте прошлое сегодня.
Благодарности
Спасибо группе аннотаторов, которые помогли нам аннотировать воздействие на задачи, в том числе Мухаммаду Ахмеду Саиду, Бонгане Зита, Мерве Озен Шенен, Джей-Джею и Питеру Хешеле. Мы также благодарим Лорин Фулд, Эшли Глат, Майкла Лампе и Джулию Сассер за отличную помощь в исследованиях. Мы благодарим Майлза Брандейджа за ценные отзывы об этой статье.
Мы благодарим Тодора Маркова и Вика Гоэла за настройку инфраструктуры, которую мы используем для запуска наших рубрик с GPT-4. Мы благодарим Ламу Ахмад, Дональда Баконга, Сета Бенцелла, Эрика Бриньолфссона, Парфе Элунду-Эньеге, Карла Фрея, Сару Жиру, Джиллиан Хэдфилд, Йоханнеса Хайдеке, Алана Хики, Эрика Хорвица, Шэнли Ху, Ашьяну Качра, Кристину Ким, Катю Клинову, Дэниела Кокотайло, Гретхен Крюгер, Майкла Лампе, Аалока Мехта, Лариссу Скьяво, Дэниела Селсама, Сару Шокер, Прасанну Тамбе и Джеффа Ву за отзывы и правки на различных этапах проекта.
Заявление о помощи LLM
GPT-4 и ChatGPT использовались для помощи в написании, программировании и форматировании в этом проекте.
Приложение A. Рубрикация воздействия
# E Таксономия воздействия
Рассмотрим самую мощную большую языковую модель (LLM) OpenAI. Эта модель может выполнять множество задач, которые можно сформулировать как имеющие текстовый ввод и текстовый вывод, где контекст для ввода может быть выражен в 2000 слов. Модель также не может использовать актуальные факты (те, которые были получены <1 года назад), если они не указаны во вводе.
Представьте, что вы работник со средним уровнем опыта в своей роли, пытающийся выполнить данную задачу. У вас есть доступ к LLM, а также к любому другому существующему программному обеспечению или компьютерному оборудованию, упомянутому в задаче. У вас также есть доступ к любым общедоступным техническим средствам, доступным через ноутбук (например, микрофон, динамики и т. д.). У вас нет доступа к каким-либо другим физическим инструментам или материалам.
Пожалуйста, пометьте данную задачу в соответствии с таксономией ниже.
## E0 — Отсутствие воздействия
Помечайте задачи E0, если прямой доступ к LLM через интерфейс, такой как ChatGPT или площадка OpenAI, не может сократить время, необходимое для выполнения этой задачи с эквивалентным качеством, наполовину или более.
Если задача требует высокой степени человеческого взаимодействия (например, личные демонстрации), то она должна быть классифицирована как E0.
## E1 — Прямое воздействие
Помечайте задачи El, если прямой доступ к LLM через интерфейс, такой как ChatGPT или площадка OpenAI, сам по себе может сократить время, необходимое для выполнения задачи с эквивалентным качеством, как минимум наполовину. Сюда входят задачи, которые можно свести к: - Написанию и преобразованию текста и кода в соответствии со сложными инструкциями, - Предоставлению правок к существующему тексту или коду в соответствии со спецификациями, - Написанию кода, который может помочь выполнить задачу, которая раньше выполнялась вручную, - Переводу текста с одного языка на другой, - Обобщению документов средней длины, - Предоставлению обратной связи по документам, - Ответам на вопросы о документе или - Генерации вопросов, которые пользователь может захотеть задать о документе.
## E2 — Воздействие приложений на базе LLM
Помечайте задачи E2, если доступ к LLM сам по себе не может сократить время, необходимое для выполнения задачи, как минимум наполовину, но можно легко представить дополнительное программное обеспечение, которое можно было бы разработать на основе LLM и которое сократило бы время, необходимое для выполнения задачи, наполовину. Это программное обеспечение может включать такие возможности, как: - Обобщение документов объемом более 2000 слов и ответы на вопросы об этих документах - Извлечение актуальных фактов из Интернета и использование этих фактов в сочетании с возможностями LLM - Поиск по существующим знаниям, данным или документам организации и извлечение информации.
Примеры программного обеспечения, созданного на основе LLM, которое может помочь выполнять рабочие действия, включают: - Программное обеспечение, созданное для компании по производству товаров для дома, которое быстро обрабатывает и обобщает их актуальные внутренние данные в индивидуальном порядке для информирования о продукте или маркетинговых решениях - Программное обеспечение, способное предлагать ответы в режиме реального времени для операторов службы поддержки клиентов, общающихся с клиентами в интерфейсе службы поддержки клиентов своей компании - Программное обеспечение, созданное для юридических целей, которое может быстро агрегировать и обобщать все предыдущие дела в конкретной области права и писать юридические исследовательские записки, адаптированные к потребностям юридической фирмы - Программное обеспечение, специально разработанное для учителей, которое позволяет им вводить рубрику оценки и загружать текстовые файлы всех эссе учащихся, а программное обеспечение выставляет оценку за каждое эссе - Программное обеспечение, которое извлекает актуальные факты из Интернета и использует возможности LLM для вывода сводок новостей на разных языках.
## E3 — Воздействие с учетом возможностей распознавания изображений
Предположим, у вас есть доступ как к LLM, так и к системе, которая может просматривать, подписывать и создавать изображения. Эта система не может принимать видео в качестве входных данных. Эта система не может точно извлекать очень подробную информацию из входных изображений, например, измерения размеров на изображении. Помечайте задачи как E3, если есть значительное сокращение времени, необходимого для выполнения задачи, при наличии доступа к LLM и этим возможностям распознавания изображений: - Чтение текста из PDF-файлов, - Сканирование изображений или - Создание или редактирование цифровых изображений в соответствии с инструкциями.
## Примеры аннотаций:
Профессия: Инспекторы, тестеры, сортировщики, пробоотборщики и взвешивающие. Задача: Отрегулировать, очистить или отремонтировать продукты или технологическое оборудование для устранения дефектов, обнаруженных во время проверок. Оценка (E0/E1/E2/E3): E0. Пояснение: Модель не имеет доступа к какой-либо физической форме, и более половины задачи (регулировка, очистка и ремонт оборудования) требует рук или другого физического воплощения.
Профессия: Специалисты по компьютерным и информационным исследованиям. Задача: Применять теоретические знания и инновации для создания или применения новых технологий, таких как адаптация принципов применения компьютеров для новых целей. Оценка (E0/E1/E2/E3): E1. Пояснение: Модель может усваивать теоретические знания во время обучения как часть своей общей базы знаний, а принципы адаптации могут быть отражены в текстовом вводе в модель.
Деятельность: Бронирование столиков в ресторане. Оценка (E0/E1/E2/E3): E2. Пояснение: Технология автоматизации для этого уже существует (например, Resy), и неясно, что LLM предлагает помимо использования этой технологии (без изменений). При этом вы можете создать нечто, что позволит вам попросить LLM сделать бронирование на Resy за вас. (E3)
Деятельность: Ведение переговоров о покупках или контрактах. Оценка (E0/E1/E2/E3): E2. Пояснение: Вы можете попросить каждую сторону изложить свою точку зрения, а затем передать это LLM для разрешения любых споров (E3). При этом многим людям придется согласиться на использование новых технологических инструментов для этого (система).
Профессия: Аллергологи и иммунологи. Задача: Назначать лекарства, такие как антигистаминные, антибиотики, а также назальные, оральные, топические или ингаляционные глюкокортикостероиды. Оценка (E0/E1/E2/E3): E2. Пояснение: Модель может предоставлять предположения для различных диагнозов и выписывать рецепты и истории болезни. Однако по-прежнему требуется участие человека, использующего свои суждения и знания для принятия окончательного решения.
Приложение B. O*NET Определения базовых навыков
Базовые навыки
Развитые способности, которые способствуют обучению или более быстрому приобретению знаний.
Содержание
Базовые структуры, необходимые для работы с более конкретными навыками и их приобретения в различных областях.
- Понимание прочитанного — Понимание письменных предложений и абзацев в документах, связанных с работой.
- Активное слушание — Уделять полное внимание тому, что говорят другие люди, не торопясь, чтобы понять суть сказанного, задавая вопросы по мере необходимости и не перебивая в неподходящее время.
- Письмо — Эффективное письменное общение в соответствии с потребностями аудитории.
- Говорение — Разговор с другими людьми для эффективной передачи информации.
- Математика — Использование математики для решения задач.
- Наука — Использование научных правил и методов для решения задач.
Процесс
Процедуры, которые способствуют более быстрому приобретению знаний и навыков в различных областях
- Критическое мышление — Использование логики и рассуждений для выявления сильных и слабых сторон альтернативных решений, выводов или подходов к проблемам.
- Активное обучение — Понимание последствий новой информации для текущего и будущего решения проблем и принятия решений.
- Стратегии обучения — Выбор и использование методов и процедур обучения/инструктажа, подходящих для ситуации при изучении или преподавании нового.
- Мониторинг — Мониторинг/оценка собственной производительности, производительности других лиц или организаций для внесения улучшений или принятия корректирующих мер.
Межфункциональные навыки
Примечание: Мы выбрали только программирование из списка межфункциональных навыков из-за наших предварительных знаний о способностях моделей к программированию.
- Программирование — Написание компьютерных программ для различных целей.
| Медианный доход | Кол-во работников (тыс.) | Η α | M α | Η β | M β | Η ζ | M ζ | |
|---|---|---|---|---|---|---|---|---|
| Нет формального образования | 31 900 | 36 187 | 0,05 | 0,06 | 0,10 | 0,10 | 0,15 | 0,15 |
| Среднее образование или эквивалент | 45 470 | 67 033 | 0,09 | 0,13 | 0,20 | 0,25 | 0,31 | 0,37 |
| Аттестат о среднем специальном образовании | 48 315 | 9 636 | 0,07 | 0,15 | 0,19 | 0,28 | 0,31 | 0,41 |
| Неполное высшее образование | 40 970 | 2 898 | 0,23 | 0,34 | 0,39 | 0,53 | 0,55 | 0,72 |
| Степень младшего специалиста | 60 360 | 3 537 | 0,12 | 0,14 | 0,31 | 0,36 | 0,49 | 0,59 |
| Степень бакалавра | 78 375 | 71 698 | 0,23 | 0,17 | 0,47 | 0,51 | 0,70 | 0,84 |
| Степень магистра | 79 605 | 3 216 | 0,26 | 0,14 | 0,46 | 0,44 | 0,66 | 0,74 |
| Докторская или ученая степень | 82 420 | 5 290 | 0,21 | 0,13 | 0,41 | 0,43 | 0,60 | 0,74 |
Таблица 10: Средние оценки воздействия для профессий, сгруппированные по типичному образованию, необходимому для работы по профессии. Наряду с оценками воздействия мы отображаем медиану среднего годового дохода для каждой профессии, а также общее количество работников в каждой группе в тысячах.
Приложение C. Воздействие на промышленность и производительность
На Рисунках 6 и 7 показано общее средневзвешенное по занятости относительное воздействие на отрасли с 3-значным кодом NAICS в соответствии с оценками людей и GPT-4 соответственно (на основе нашей рубрики воздействия). Потенциальное воздействие присутствует почти во всех отраслях, с широкой неоднородностью. Оба метода в целом согласуются по относительному воздействию: обработка данных, обработка информации и больницы имеют высокий уровень воздействия.9
9Агрегирование выполняется в соответствии с методом β, описанным выше. Веса задач для дополнительных задач составляют половину весов основных задач, в сумме давая единицу в рамках профессии. Количество занятых по профессиям используется в качестве весов для построения показателей воздействия на уровне отрасли.
Недавний рост производительности (как совокупной производительности факторов производства, так и производительности труда), по-видимому, не коррелирует с воздействием. На Рисунках C и C показано незначительное соотношение между ростом производительности с 2012 года и текущим воздействием LLM по оценке модели. Высокая корреляция между уже быстрорастущими производительными отраслями и воздействием могла бы означать усугубление «болезни издержек» Баумоля. Другими словами, если LLM, вероятно, будут по-разному увеличивать производительность в разных отраслях, возникает опасение, что наиболее производительные отрасли станут еще более производительными. При неэластичном спросе на продукцию этих отраслей наиболее производительные сектора сократятся в пропорции к вводимым ресурсам в экономике. Мы не видим особых оснований полагать, что это произойдет. Рост производительности с 2012 года и воздействие технологий LLM, по-видимому, не связаны между собой.10
10Как и выше, агрегирование выполняется в соответствии с методом β, описанным выше. Веса задач для дополнительных задач составляют половину весов основных задач, в сумме давая единицу в рамках профессии. Количество занятых по профессиям используется в качестве весов для построения показателей воздействия на уровне отрасли.
Воздействие больших языковых моделей по отраслям (оценка произведена разметчиками людьми)
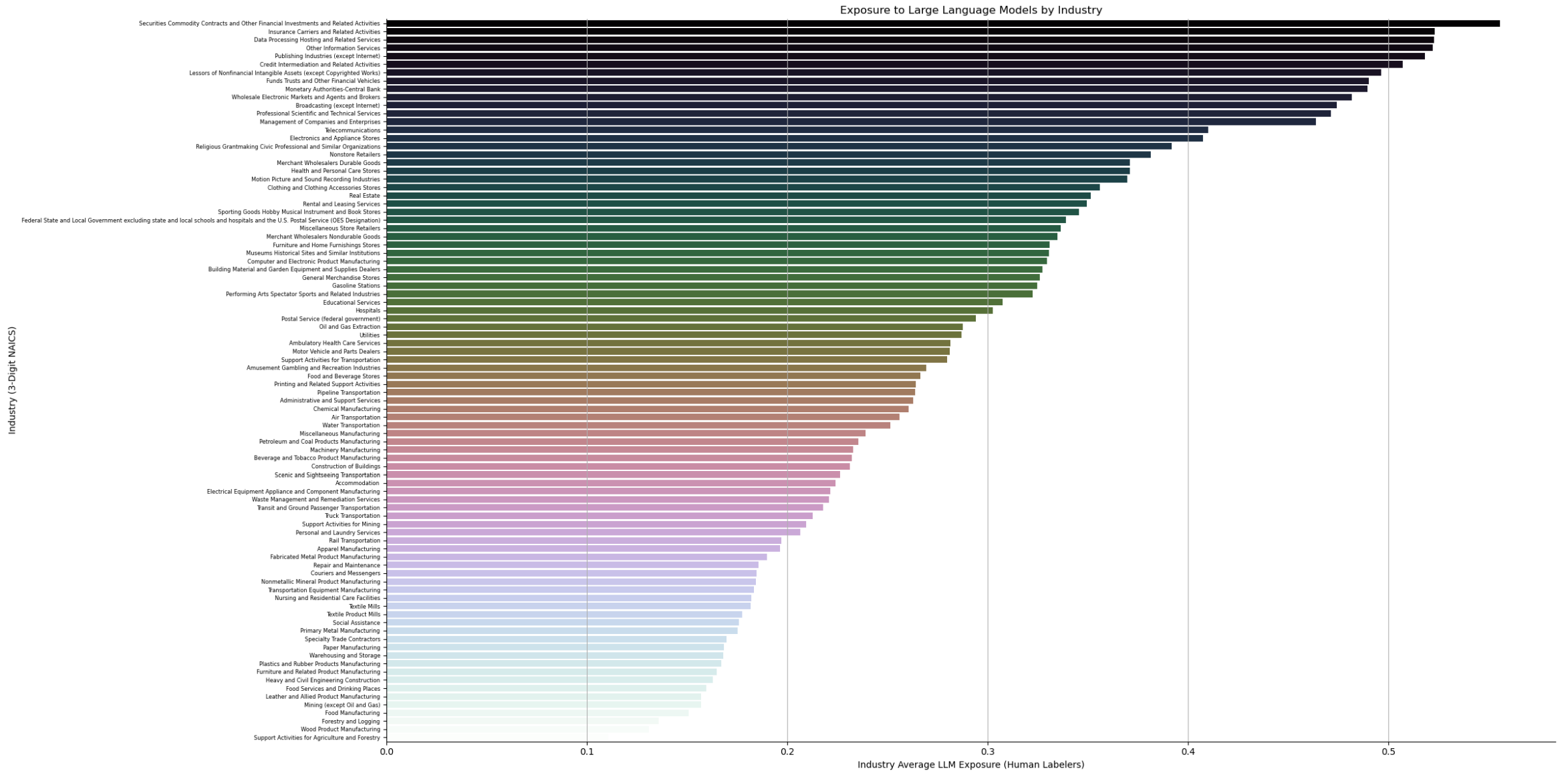
Наверху списка наибольшее воздействие; внизу списка наименьшее воздействие:
- Деятельность по операциям с товарными контрактами и прочие виды инвестиционной деятельности и связанные с ними виды деятельности
- Страховые компании и связанные с ними виды деятельности
- Обработка данных, хостинг и связанные с ними услуги
- Прочие информационные услуги
- Издательская деятельность (кроме Интернета)
- Кредитное посредничество и связанные с ним виды деятельности
- Аренда нефинансовых нематериальных активов (кроме объектов авторского права)
- Фонды, трасты и прочие финансовые инструменты
- Денежно-кредитное регулирование - Центральный банк
- Оптовые электронные рынки, агенты и брокеры
- Вещание (кроме Интернета)
- Профессиональные, научные и технические услуги
- Управление компаниями и предприятиями
- Телекоммуникации
- Магазины электроники и бытовой техники
- Религиозные, благотворительные, гражданские, профессиональные и аналогичные организации
- Розничные торговцы, не являющиеся магазинами
- Оптовые торговцы товарами длительного пользования
- Магазины товаров для здоровья и личной гигиены
- Кино- и звукозаписывающая индустрия
- Магазины одежды и аксессуаров
- Недвижимость
- Услуги по аренде и лизингу
- Магазины спортивных товаров, товаров для хобби, музыкальных инструментов и книг
- Федеральное, региональное и местное самоуправление, кроме региональных и местных школ и больниц, а также Почтовой службы США (обозначение OES)
- Различные розничные магазины
- Оптовые торговцы товарами кратковременного пользования
- Мебельные магазины и магазины товаров для дома
- Музеи, исторические места и аналогичные учреждения
- Производство компьютеров и электронных товаров
- Продавцы строительных материалов, садового инвентаря и расходных материалов
- Универсальные магазины
- Автозаправочные станции
- Исполнительское искусство, зрелищные виды спорта и связанные с ними отрасли
- Образовательные услуги
- Больницы
- Почтовая служба (федеральное правительство)
- Добыча нефти и газа
- Коммунальные услуги
- Амбулаторное медицинское обслуживание
- Дилеры автомобилей и запчастей
- Вспомогательная деятельность по поддержке перевозок
- Индустрия развлечений, азартных игр и отдыха
- Продовольственные магазины и магазины напитков
- Полиграфическая и сопутствующая вспомогательная деятельность
- Трубопроводный транспорт
- Административные и вспомогательные услуги
- Химическое производство
- Воздушный транспорт
- Водный транспорт
- Разное производство
- Производство нефтепродуктов и угольных продуктов
- Машиностроение
- Производство напитков и табачных изделий
- Строительство зданий
- Живописные и экскурсионные перевозки
- Гостиницы
- Производство электрооборудования, бытовой техники и комплектующих
- Услуги по управлению отходами и рекультивации
- Транзитные и наземные пассажирские перевозки
- Грузовые автомобильные перевозки
- Вспомогательная деятельность по поддержке добычи полезных ископаемых
- Персональные услуги и услуги прачечных
- Железнодорожный транспорт
- Производство одежды
- Производство металлоконструкций
- Ремонт и техническое обслуживание
- Курьеры и посыльные
- Производство нерудных полезных ископаемых
- Производство транспортного оборудования
- Уход в домах престарелых и учреждениях по уходу
- Текстильные фабрики
- Текстильные фабрики
- Социальная помощь
- Производство первичных металлов
- Специализированные подрядчики
- Производство бумаги
- Складское хозяйство и хранение
- Производство пластмасс и резинотехнических изделий
- Производство мебели и сопутствующих товаров
- Тяжелое и гражданское строительство
- Предприятия общественного питания и питейные заведения
- Производство кожи и сопутствующих товаров
- Горнодобывающая промышленность (кроме нефти и газа)
- Пищевая промышленность
- Лесное хозяйство и лесозаготовки
- Производство изделий из дерева
- Вспомогательная деятельность в сельском и лесном хозяйстве
Воздействие больших языковых моделей по отраслям (оценка произведена c помощью GPT-4)
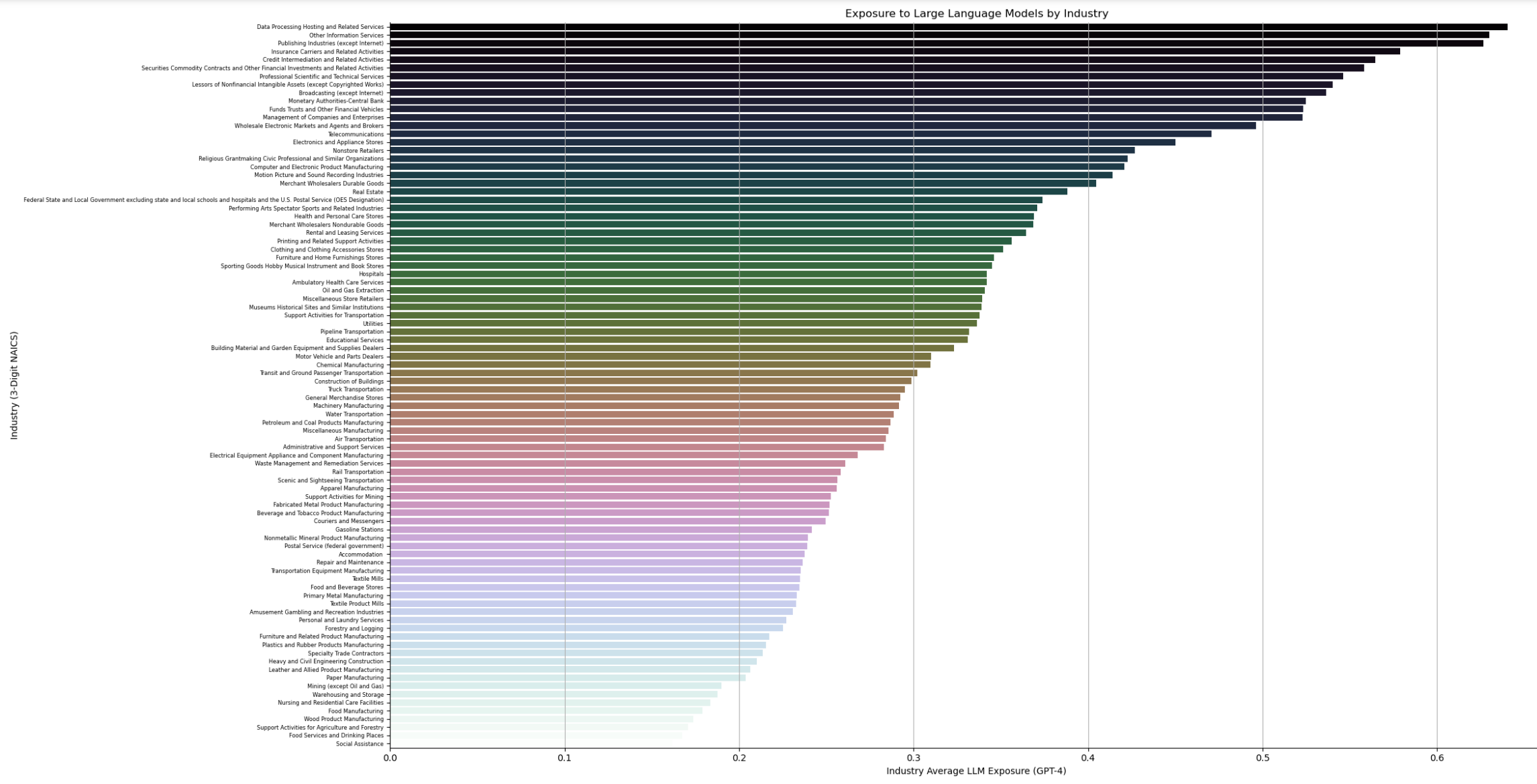
Наверху списка наибольшее воздействие; внизу списка наименьшее воздействие:
- Обработка данных, хостинг и связанные с ними услуги
- Прочие информационные услуги
- Издательская деятельность (кроме Интернета)
- Страховые компании и связанные с ними виды деятельности
- Кредитное посредничество и связанные с ним виды деятельности
- Деятельность по операциям с ценными бумагами, товарными контрактами и прочие виды инвестиционной деятельности и связанные с ними виды деятельности
- Профессиональные, научные и технические услуги
- Аренда нефинансовых нематериальных активов (кроме объектов авторского права)
- Вещание (кроме Интернета)
- Денежно-кредитное регулирование - Центральный банк
- Фонды, трасты и прочие финансовые инструменты
- Управление компаниями и предприятиями
- Оптовые электронные рынки, агенты и брокеры
- Телекоммуникации
- Магазины электроники и бытовой техники
- Розничные торговцы, не являющиеся магазинами
- Религиозные, благотворительные, гражданские, профессиональные и аналогичные организации
- Производство компьютеров и электронных товаров
- Кино- и звукозаписывающая индустрия
- Оптовые торговцы товарами длительного пользования
- Недвижимость
- Федеральное, региональное и местное самоуправление, кроме региональных и местных школ и больниц, а также Почтовой службы США (обозначение OES)
- Исполнительское искусство, зрелищные виды спорта и связанные с ними отрасли
- Магазины товаров для здоровья и личной гигиены
- Оптовые торговцы товарами кратковременного пользования
- Услуги по аренде и лизингу
- Полиграфическая и сопутствующая вспомогательная деятельность
- Магазины одежды и аксессуаров
- Мебельные магазины и магазины товаров для дома
- Магазины спортивных товаров, товаров для хобби, музыкальных инструментов и книг
- Больницы
- Амбулаторное медицинское обслуживание
- Добыча нефти и газа
- Различные розничные магазины
- Музеи, исторические места и аналогичные учреждения
- Вспомогательная деятельность по поддержке перевозок
- Коммунальные услуги
- Трубопроводный транспорт
- Образовательные услуги
- Продавцы строительных материалов, садового инвентаря и расходных материалов
- Дилеры автомобилей и запчастей
- Химическое производство
- Транзитные и наземные пассажирские перевозки
- Строительство зданий
- Грузовые автомобильные перевозки
- Универсальные магазины
- Машиностроение
- Водный транспорт
- Производство нефтепродуктов и угольных продуктов
- Разное производство
- Воздушный транспорт
- Административные и вспомогательные услуги
- Производство электрооборудования, бытовой техники и комплектующих
- Услуги по управлению отходами и рекультивации
- Железнодорожный транспорт
- Живописные и экскурсионные перевозки
- Производство одежды
- Вспомогательная деятельность по поддержке добычи полезных ископаемых
- Производство металлоконструкций
- Производство напитков и табачных изделий
- Курьеры и посыльные
- Автозаправочные станции
- Производство нерудных полезных ископаемых
- Почтовая служба (федеральное правительство)
- Гостиницы
- Ремонт и техническое обслуживание
- Производство транспортного оборудования
- Текстильные фабрики
- Продовольственные магазины и магазины напитков
- Производство первичных металлов
- Текстильные фабрики
- Индустрия развлечений, азартных игр и отдыха
- Персональные услуги и услуги прачечных
- Лесное хозяйство и лесозаготовки
- Производство мебели и сопутствующих товаров
- Производство пластмасс и резинотехнических изделий
- Специализированные подрядчики
- Тяжелое и гражданское строительство
- Производство кожи и сопутствующих товаров
- Производство бумаги
- Горнодобывающая промышленность (кроме нефти и газа)
- Складское хозяйство и хранение
- Уход в домах престарелых и учреждениях по уходу
- Пищевая промышленность
- Производство изделий из дерева
- Вспомогательная деятельность в сельском и лесном хозяйстве
- Предприятия общественного питания и питейные заведения
- Социальная помощь
Приложение D. Профессии без задач, подверженных воздействию
Все 34 профессии, для которых ни один из наших показателей не выявил задач, подверженных воздействию
- Сельскохозяйственное оборудование
- Спортсмены и спортивные участники соревнований
- Автомеханики и ремонтники стекол
- Механики автобусов и грузовиков, а также специалисты по дизельным двигателям
- Бетонщики и плиточники
- Повара фаст-фуда
- Резчики и триммеры, ручные
- Операторы буровых установок, нефть и газ
- Работники столовых и кафетериев, а также помощники барменов
- Посудомойщики
- Операторы земснарядов
- Электромонтажники
- Машинисты экскаваторов и погрузчиков, а также операторы грейферов в горнодобывающей промышленности
- Укладчики полов, кроме ковров, дерева и твердой плитки
- Формовщики и литейщики
- Каменщики, блочники, каменщики и укладчики плитки и мрамора
- Разнорабочие-строители
- Разнорабочие-маляры, штукатуры и лепщики
- Разнорабочие-сантехники, трубопроводчики и паропроводчики
- Кровельщики
- Мясники и резчики мяса, птицы и рыбы
- Мотомеханики
- Операторы сваебойных машин
- Разливщики и формовщики металла
- Операторы путеукладчиков
- Ремонтники огнеупорных материалов, кроме каменщиков
- Крепильщики, нефть и газ
- Убойщики и упаковщики мяса
- Каменщики
- Шиномонтажники и ремонтники шин
- Бурильщики скважин
Ссылки
Abid, A., Farooqi, M., and Zou, J. (2021). Persistent anti-muslim bias in large language models. In Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society, AIES ‘21, page 298–306, New York, NY, USA. Association for Computing Machinery.
Acemoglu, D. (2002). Technical change, inequality, and the labor market. Journal of Economic Literature, 40.
Acemoglu, D. and Autor, D. (2011a). Skills, tasks and technologies: Implications for employment and earnings. In Handbook of labor economics, volume 4, pages 1043–1171. Elsevier.
Acemoglu, D. and Autor, D. (2011b). Skills, Tasks and Technologies: Implications for Employment and Earnings. In Ashenfelter, O. and Card, D., editors, Handbook of Labor Economics, volume 4 of Handbook of Labor Economics, chapter 12, pages 1043–1171. Elsevier.
Acemoglu, D., Autor, D., Hazell, J., and Restrepo, P. (2020). Ai and jobs: Evidence from online vacancies. Technical report, National Bureau of Economic Research.
Acemoglu, D. and Restrepo, P. (2018). The race between man and machine: Implications of technology for growth, factor shares, and employment. American economic review, 108(6):1488–1542.
Acemoglu, D. and Restrepo, P. (2019). Automation and new tasks: How technology displaces and reinstates labor. Journal of Economic Perspectives, 33(2):3-30.
Acemoglu, D. and Restrepo, P. (2022a). Demographics and automation. The Review of Economic Studies, 89(1):1-44.
Acemoglu, D. and Restrepo, P. (2022b). Tasks, automation, and the rise in us wage inequality. Econometrica, 90(5):1973-2016.
Aghion, P., Jones, B. F., and Jones, C. I. (2018). Artificial intelligence and economic growth. In The economics of artificial intelligence: An agenda, pages 237–282. University of Chicago Press.
Agrawal, A. K., Gans, J. S., and Goldfarb, A. (2021). Ai adoption and system-wide change. Technical report, National Bureau of Economic Research.
Arntz, M., Gregory, T., and Zierahn, U. (2017). Revisiting the risk of automation. Economics Letters, 159:157-160.
Autor, D., Chin, C., Salomons, A. M., and Seegmiller, B. (2022a). New frontiers: The origins and content of new work, 1940–2018. Technical report, National Bureau of Economic Research.
Autor, D., Mindell, D. A., and Reynolds, E. B. (2022b). The Work of the Future: Building Better Jobs in an Age of Intelligent Machines. The MIT Press.
Autor, D. H., Katz, L. F., and Kearney, M. S. (2006). The polarization of the us labor market. American economic review, 96(2):189–194.
Autor, D. H., Levy, F., and Murnane, R. J. (2003). The skill content of recent technological change: An empirical exploration. The Quarterly journal of economics, 118(4):1279–1333.
Babina, T., Fedyk, A., He, A., and Hodson, J. (2021). Artificial intelligence, firm growth, and product innovation. Firm Growth, and Product Innovation (November 9, 2021).
Bai, Y., Jones, A., Ndousse, K., Askell, A., Chen, A., DasSarma, N., Drain, D., Fort, S., Ganguli, D., Henighan, T., Joseph, N., Kadavath, S., Kernion, J., Conerly, T., El-Showk, S., Elhage, N., Hatfield-Dodds, Z., Hernandez, D., Hume, T., Johnston, S., Kravec, S., Lovitt, L., Nanda, N., Olsson, C., Amodei, D., Brown, T., Clark, J., McCandlish, S., Olah, C., Mann, B., and Kaplan, J. (2022). Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback. arXiv:2204.05862 [cs].
Baumol, W. J. (2012). The cost disease: Why computers get cheaper and health care doesn’t. Yale university press.
Benzell, S. G., Kotlikoff, L. J., LaGarda, G., and Ye, V. Y. (2021). Simulating endogenous global automation. Working Paper 29220, National Bureau of Economic Research.
Bessen, J. (2018). Artificial intelligence and jobs: The role of demand. In The economics of artificial intelligence: an agenda, pages 291–307. University of Chicago Press.
BLS (2022). Employment by detailed occupation.
BLS (2023a). Demographic characteristics (cps).
BLS (2023b). Occupational outlook handbook a-z index.
Bommasani, R., Hudson, D. A., Adeli, E., Altman, R., Arora, S., von Arx, S., Bernstein, M. S., Bohg, J., Bosselut, A., Brunskill, E., et al. (2021). On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258.
Bresnahan, T. (2019). Artificial intelligence technologies and aggregate growth prospects.
Bresnahan, T., Greenstein, S., Brownstone, D., and Flamm, K. (1996). Technical progress and co-invention in computing and in the uses of computers. Brookings Papers on Economic Activity. Microeconomics, 1996:1-83.
Bresnahan, T. F. (1999). Computerisation and wage dispersion: an analytical reinterpretation. The economic journal, 109(456):390–415.
Bresnahan, T. F., Brynjolfsson, E., and Hitt, L. M. (2002). Information technology, workplace organization, and the demand for skilled labor: Firm-level evidence. The quarterly journal of economics, 117(1):339–376.
Bresnahan, T. F. and Trajtenberg, M. (1995). General purpose technologies ‘engines of growth’? Journal of econometrics, 65(1):83–108.
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. (2020). Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
Brynjolfsson, E., Frank, M. R., Mitchell, T., Rahwan, I., and Rock, D. (2023). Quantifying the Distribution of Machine Learning’s Impact on Work. Forthcoming.
Brynjolfsson, E. and Mitchell, T. (2017). What can machine learning do? workforce implications. Science, 358(6370):1530–1534.
Brynjolfsson, E., Mitchell, T., and Rock, D. (2018). What can machines learn, and what does it mean for occupations and the economy? AEA Papers and Proceedings, 108:43–47.
Brynjolfsson, E., Rock, D., and Syverson, C. (2021). The productivity j-curve: How intangibles complement general purpose technologies. American Economic Journal: Macroeconomics, 13(1):333–72.
Chase, H. (2022). LangChain.
Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H. P. d. O., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., et al. (2021). Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374.
Cheng, Z., Lee, D., and Tambe, P. (2022). Innovae: Generative ai for understanding patents and innovation. Available at SSRN.
| Chow, A. R. (2023). Why ChatGPT Is the Fastest Growing Web Platform Ever | Time. |
Cockburn, I. M., Henderson, R., and Stern, S. (2018). The impact of artificial intelligence on innovation: An exploratory analysis. In The economics of artificial intelligence: An agenda, pages 115–146. University of Chicago Press.
Constantz, J. (2023). Nearly a third of white collar workers have tried chatgpt or other ai programs, according to a new survey.
David, P. A. (1990). The dynamo and the computer: an historical perspective on the modern productivity paradox. The American Economic Review, 80(2):355–361.
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. (2019). Bert: Pre-training of deep bidirectional transformers for language understanding. ArXiv, abs/1810.04805.
Dixon, J., Hong, B., and Wu, L. (2021). The robot revolution: Managerial and employment consequences for firms. Management Science, 67(9):5586–5605.
Feigenbaum, J. J. and Gross, D. P. (2021). Organizational frictions and increasing returns to automation: Lessons from at&t in the twentieth century. Technical report, National Bureau of Economic Research.
Felten, E., Raj, M., and Seamans, R. (2023). How will language modelers like chatgpt affect occupations and industries? arXiv preprint arXiv:2303.01157.
Felten, E. W., Raj, M., and Seamans, R. (2018). A method to link advances in artificial intelligence to occupational abilities. AEA Papers and Proceedings, 108:54–57.
Frey, C. B. (2019). The technology trap. In The Technology Trap. Princeton University Press.
Frey, C. B. and Osborne, M. A. (2017). The future of employment: How susceptible are jobs to computerisation? Technological Forecasting and Social Change, 114(C):254-280.
Goldfarb, A., Taska, B., and Teodoridis, F. (2023). Could machine learning be a general purpose technology? a comparison of emerging technologies using data from online job postings. Research Policy, 52(1):104653.
Goldstein, J. A., Sastry, G., Musser, M., DiResta, R., Gentzel, M., and Sedova, K. (2023). Generative language models and automated influence operations: Emerging threats and potential mitigations.
Grace, K., Salvatier, J., Dafoe, A., Zhang, B., and Evans, O. (2018). When will ai exceed human performance? evidence from ai experts. Journal of Artificial Intelligence Research, 62:729–754.
Hernandez, D., Kaplan, J., Henighan, T., and McCandlish, S. (2021). Scaling laws for transfer. arXiv preprint arXiv:2102.01293.
Horton, J. J. (2023). Large language models as simulated economic agents: What can we learn from homo silicus? arXiv preprint arXiv:2301.07543.
Huang, M.-H. and Rust, R. T. (2018). Artificial intelligence in service. Journal of service research, 21(2):155-172.
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. (2020). Scaling laws for neural language models. arXiv preprint arXiv:2001.08361.
Katz, L. F. and Murphy, K. M. (1992). Changes in relative wages, 1963–1987: supply and demand factors. The quarterly journal of economics, 107(1):35–78.
Khlaaf, H., Mishkin, P., Achiam, J., Krueger, G., and Brundage, M. (2022). A hazard analysis framework for code synthesis large language models.
Klinova, K. and Korinek, A. (2021). Ai and shared prosperity. In AIES 2021 - Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society.
Kogan, L., Papanikolaou, D., Schmidt, L. D. W., and Seegmiller, B. (2021). Technology, vintage-specific human capital, and labor displacement: Evidence from linking patents with occupations. Working Paper 29552, National Bureau of Economic Research.
Korinek, A. (2023). Language models and cognitive automation for economic research. Technical report, National Bureau of Economic Research.
Korinek, A. and Stiglitz, J. E. (2018). Artificial intelligence and its implications for income distribution and unemployment. In The economics of artificial intelligence: An agenda, pages 349–390. University of Chicago Press.
Lipsey, R. G., Carlaw, K. I., and Bekar, C. T. (2005). Economic transformations: general purpose technologies and long-term economic growth. Oup Oxford.
Meindl, B., Frank, M. R., and Mendonça, J. (2021). Exposure of occupations to technologies of the fourth industrial revolution. arXiv preprint arXiv:2110.13317.
Mialon, G., Dessì, R., Lomeli, M., Nalmpantis, C., Pasunuru, R., Raileanu, R., Rozière, B., Schick, T., Dwivedi-Yu, J., Celikyilmaz, A., et al. (2023). Augmented language models: a survey. arXiv preprint arXiv:2302.07842.
Moll, B., Rachel, L., and Restrepo, P. (2021). Uneven growth: Automation’s impact on income and wealth inequality. SSRN Electronic Journal.
Mollick, E. R. and Mollick, L. (2022). New modes of learning enabled by ai chatbots: Three methods and assignments. Available at SSRN.
Noy, S. and Zhang, W. (2023). Experimental evidence on the productivity effects of generative artificial intelligence. Available at SSRN 4375283.
ONET (2023). Onet 27.2 database.
OpenAI (2022). Introducing chatgpt.
OpenAI (2023a). Gpt-4 system card. Technical report, OpenAI.
OpenAI (2023b). Gpt-4 technical report. Technical report, OpenAI.
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C. L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al. (2022). Training language models to follow instructions with human feedback. arXiv preprint arXiv:2203.02155.
Peng, S., Kalliamvakou, E., Cihon, P., and Demirer, M. (2023). The impact of ai on developer productivity: Evidence from github copilot. arXiv preprint arXiv:2302.06590.
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I., et al. (2019). Language models are unsupervised multitask learners. OpenAI blog, 1(8):9.
ResumeBuilder.com (2023). 1 in 4 companies have already replaced workers with chatgpt.
Rock, D. (2019). Engineering value: The returns to technological talent and investments in artificial intelligence. Available at SSRN 3427412.
Schick, T., Dwivedi-Yu, J., Dessì, R., Raileanu, R., Lomeli, M., Zettlemoyer, L., Cancedda, N., and Scialom, T. (2023). Toolformer: Language models can teach themselves to use tools. arXiv preprint arXiv:2302.04761.
Schramowski, P., Turan, C., Andersen, N., Rothkopf, C. A., and Kersting, K. (2022). Large pre-trained language models contain human-like biases of what is right and wrong to do. Nature Machine Intelligence, 4(3):258-268.
Shahaf, D. and Horvitz, E. (2010). Generalized task markets for human and machine computation. Proceedings of the AAAI Conference on Artificial Intelligence.
Singla, A. K., Horvitz, E., Kohli, P., and Krause, A. (2015). Learning to hire teams. In AAAI Conference on Human Computation & Crowdsourcing.
Solaiman, I., Brundage, M., Clark, J., Askell, A., Herbert-Voss, A., Wu, J., Radford, A., Krueger, G., Kim, J. W., Kreps, S., McCain, M., Newhouse, A., Blazakis, J., McGuffie, K., and Wang, J. (2019). Release strategies and the social impacts of language models.
Sorensen, T., Robinson, J., Rytting, C., Shaw, A., Rogers, K., Delorey, A., Khalil, M., Fulda, N., and Wingate, D. (2022). An information-theoretic approach to prompt engineering without ground truth labels. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics.
Thoppilan, R., De Freitas, D., Hall, J., Shazeer, N., Kulshreshtha, A., Cheng, H.-T., Jin, A., Bos, T., Baker, L., Du, Y., et al. (2022). Lamda: Language models for dialog applications. arXiv preprint arXiv:2201.08239.
Tolan, S., Pesole, A., Martínez-Plumed, F., Fernández-Macías, E., Hernández-Orallo, J., and Gómez, E. (2021). Measuring the occupational impact of ai: tasks, cognitive abilities and ai benchmarks. Journal of Artificial Intelligence Research, 71:191–236.
Van Reenen, J. (2011). Wage inequality, technology and trade: 21st century evidence. Labour economics, 18(6):730-741.
Webb, M. (2020). The impact of artificial intelligence on the labor market. Working paper, Stanford University.
Weidinger, L. et al. (2021). Ethical and social risks of harm from language models. arXiv:2112.04359 [cs].
Weidinger, L., Uesato, J., Rauh, M., Griffin, C., Huang, P.-S., Mellor, J., Glaese, A., Cheng, M., Balle, B., Kasirzadeh, A., Biles, C., Brown, S., Kenton, Z., Hawkins, W., Stepleton, T., Birhane, A., Hendricks, L. A., Rimell, L., Isaac, W., Haas, J., Legassick, S., Irving, G., and Gabriel, I. (2022). Taxonomy of risks posed by language models. In 2022 ACM Conference on Fairness, Accountability, and Transparency, FAccT ‘22, page 214-229, New York, NY, USA. Association for Computing Machinery.
Zolas, N., Kroff, Z., Brynjolfsson, E., McElheran, K., Beede, D. N., Buffington, C., Goldschlag, N., Foster, L., and Dinlersoz, E. (2021). Advanced technologies adoption and use by us firms: Evidence from the annual business survey. Technical report, National Bureau of Economic Research.
Посты в которых упоминается этот пост
К этой заметке нет ссылок.